
WEB缓存中间件之Redis
一、什么是NoSQL数据库?
1.1 讲在NOSQL之前
1.1.1 网站访问的前世今生
在90年代,一个网站的访问量一般都不大,用单个数据库完全可以轻松应付。 在那个时候,更多的都是静态网页,动态交互类型的网站不多。后来,随着访问量的上升,几乎大部分使用MySQL架构的网站在数据库上都开始出现了性能问题,web程序不再仅仅专注在功能上,同时也在追求性能。程序员们开始大量的使用缓存技术来缓解数据库的压力,优化数据库的结构和索引。开始比较流行的是通过文件缓存来缓解数据库压力,但是当访问量继续增大的时候,多台web机器通过文件缓存不能共享,大量的小文件缓存也带了了比较高的IO压力。在这个时候,Memcached就自然的成为一个非常时尚的技术产品。Memcached作为一个独立的分布式的缓存服务器,为多个web服务器提供了一个共享的高性能缓存服务,在Memcached服务器上,又发展了根据hash算法来进行多台Memcached缓存服务的扩展,然后又出现了一致性hash来解决增加或减少缓存服务器导致重新hash带来的大量缓存失效的弊端。
由于数据库的写入压力增加,Memcached只能缓解数据库的读取压力。读写集中在一个数据库上让数据库不堪重负,大部分网站开始使用主从复制技术来达到读写分离,通过将主数据库的数据复制到从库,从而实现将读的压力分担给从库,主库用于承担写等操作的压力。
1.1.2 RDBMS数据库的瓶颈
MySQL数据库也经常存储一些大文本字段,导致数据库表非常的大,在做数据库恢复的时候就导致非常的慢,不容易快速恢复数据库。比如1000万4KB大小的文本就接近40GB的大小,如果能把这些数据从MySQL省去,MySQL将变得非常的小。关系数据库很强大,但是它并不能很好的应付所有的应用场景。MySQL的扩展性差(需要复杂的技术来实现),大数据下IO压力大,表结构更改困难,正是当前使用MySQL的开发人员面临的问题。
1.1.3 为什么用NoSQL?
Nosql(redis)的出生和传统的关系型数据库是颇有渊源的,在早期,用户的访问数据不大的时候,后端的一台数据库完全可以支撑起整个网站的访问并发,但是随着互联网的高速发展,用于数据库的使用需求急剧增加,大量的数据需要从数据库中获取,大量的数据读取变成了一个个对数据库的IO请求,而且这些请求中大量请求都是读的请求,这对于数据库来说是一种额外的性能消耗,此时,有人就在设想,能不能参考CPU一样,利用高速缓存来解决数据的读取问题,于是redis就这么诞生了,redis和后端数据库在一起工作,当用户访问数据库的时候,会将数据反馈给用户的同时另外将数据写入到redis一份,当同样的请求来时,就不再去mysql中读取数据,而是直接在redis中去读取数据,由于redis是一个内存型的数据库,因此读取的速度也比直接在硬盘中读取要快很多,也因此加快了系统的响应速度。
使用了nosql-redis之后:
1、可以实现session的共享
2、可以实现数据库的缓存
1.2 什么是NoSQL?
1.2.1 NoSQL 概述
NoSQL(NoSQL = Not Only SQL ),意即“不仅仅是SQL”,
泛指非关系型的数据库。随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题,包括超大规模数据的存储。
1.2.2 NoSQL代表
MongDB 文档类型
Redis、Memcache 键值类型
Neo4j 图关系型
1.3 关系型数据库与NoSQL的区别?
1.3.1 RDBMS
高度组织化结构化数据
结构化查询语言(SQL)
数据和关系都存储在单独的表中。
数据操纵语言,数据定义语言
严格的一致性
基础事务
ACID
关系型数据库遵循ACID规则
A (Atomicity) 原子性
原子性很容易理解,也就是说事务里的所有操作要么全部做完,要么都不做,事务成功的条件是事务里的所有操作都成功,只要有一个操作失败,整个事务就失败,需要回滚。比如银行转账,从A账户转100元至B账户,分为两个步骤:1)从A账户取100元;2)存入100元至B账户。这两步要么一起完成,要么一起不完成,如果只完成第一步,第二步失败,钱会莫名其妙少了100元。
C (Consistency) 一致性
一致性也比较容易理解,也就是说数据库要一直处于一致的状态,事务的运行不会改变数据库原本的一致性约束。
I (Isolation) 独立性
所谓的独立性是指并发的事务之间不会互相影响,如果一个事务要访问的数据正在被另外一个事务修改,只要另外一个事务未提交,它所访问的数据就不受未提交事务的影响。比如现有有个交易是从A账户转100元至B账户,在这个交易还未完成的情况下,如果此时B查询自己的账户,是看不到新增加的100元的
D (Durability) 持久性
持久性是指一旦事务提交后,它所做的修改将会永久的保存在数据库上,即使出现宕机也不会丢失。
关系型数据库的优势:
便于理解:二维表构造非常贴近逻辑;
应用方便:支持通用的SQL(结构化查询语言)语句;
易于维护:全部由表结构组成,文件格式一致;
复杂操作:可以用SQL句子多个表之间做非常繁杂的查询;
事务管理:促使针对安全性性能很高的数据信息浏览规定得到完成。
关系型数据库存在的不足
读写性能差,尤其是海量信息的效率高读写能力;
固定不动的表构造,灵便度稍欠;
高并发读写时,硬盘I/O存在瓶颈;
可扩展性不足,不像web server和app server那样简单的添加硬件和服务节点来拓展性能和负荷工作能力。
1.3.2 NoSQL(非关系型)
非关系型数据库的优点
格式灵活:数据存储格式非常多样,应用领域广泛,而关系型数据库则只适用基础的关系模型。
性能优越:NOSQL是根据键值对的,不用历经SQL层的分析,因此 性能非常高。
可扩展性:基于键值对,数据之间耦合度极低,因此容易水平扩展。
低成本:非关系型数据库部署简易,且大部分可以开源使用。
非关系型数据库的不足:
不支持sql,学习和运用成本比较高;
弱事务处理机制;
数据结构导致复杂查询不容易实现。
1.3.3 关系型与非关系型数据库的区别
成本:Nosql数据库易部署,不用像Oracle那般花费较高成本选购。
查询速率:Nosql数据库将数据储存于缓存当中,不用历经SQL层的分析;关系型数据库将数据储存在电脑硬盘中,查询速率远不如Nosql数据库。
储存格式:Nosql的储存文件格式是key,value方式、文本文档方式、照片方式这些,能储存的对象种类灵活;关系数据库则只适用基础类型。
可扩展性:关系型数据库有join那样的多表查询机制限定造成拓展性较差。Nosql依据键值对,数据中间沒有耦合度,因此容易水平拓展。
数据一致性:非关系型数据库注重最终一致性;关系型数据库注重数据整个生命周期的强一致性。
事务处理:SQL数据库支持事务原子性粒度控制,且方便进行事务回滚;NoSQL也支持事务处理,但可靠性不足,其价值在于可扩展性和大数据量处理。
1.4 Redis
官方网站:https:#redis.io/
1.4.1 redis的介绍


Redis,英文全称是Remote Dictionary Server(远程字典服务),是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
与MySQL数据库不同的是,Redis的数据是存在内存中的。它的读写速度非常快,每秒可以处理超过10万次读写操作。因此redis被广泛应用于缓存,另外,Redis也经常用来做分布式锁。除此之外,Redis支持事务、持久化、LUA 脚本、LRU 驱动事件、多种集群方案。
Redis 是一个高性能的key-value数据库。 redis的出现,很大程度补偿了memcached这类key/value存储的不足,在部 分场合可以对关系数据库起到很好的补充作用。
Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。
1.4.2 redis的业务场景
1、[sort set]排行榜应用,取topn操作,例如sina微博热门话题
2、[List]获得最新N个数据 或 某个分类的最新数据
3、[string]计数點应用
4、[Set]/sns(social network site)获得共同好友
5、[set]防攻击系统(ip判断) 黑白名单等等
1.4.3 Redis支持的数据结构
支持存储的数据结构有
String(字符串,包含整数)
List(列表)
Hash(关联数组)
Sets(集合)
Sorted Sets(有序集合)
1.4.4 Redis的性能
1)、100 万较小的键存储字符串,大概消耗 100M 内存
2)、由于 redis 是单线程,如果服务器主机上有多个 CPU,只有一个能够使用,但并不意味着 CPU 会成为瓶颈,因为 redis 是一个比较简单的 K-V 数据存储,CPU 通常不会成为瓶颈的
3)、在常见的 linux 服务器上,500K(50 万)的并发,只需要一秒钟处理,如果主机硬件较好的情况下,每秒钟可以达到上百万的并发
1.4.5 Redis优势
1)速度快:10W QPS,基于内存,C语言实现
2)单线程:Redis工作线程只有一个线程
3)支持数据的持久化:可以将内存中的数据保持在磁盘中,重启redis服务或者服务器之后可以从备份文件中恢复数据到内存继续使用
4)支持更多的数据类型:支持string(字符串)、hash(哈希数据)、list(列表)、set(集合)、zset(有序集 合)
5)支持数据的备份:可以实现类似于数据的master-slave模式的数据备份,另外也支持使用快照 +AOF 支持更大的value数据:memcache单个key value最大只支持1MB,而redis最大支持512MB(生产 不建议超过2M,性能受影响)
6)在Redis6版本前,Redis 是单线程,而memcached是多线程,所以单机情况下没有memcached 并 发高,性能更好,但redis 支持分布式集群以实现更高的并发,单Redis实例可以实现数万并发
7)支持多种编程语言
8)功能丰富:支持Lua脚本,发布订阅,事务,pipeline等功能
9)简单:代码短小精悍(单机核心代码只有23000行左右),单线程开发容易,不依赖外部库,使用简单
10)主从复制
11)支持高可用和分布式
12)支持集群横向扩展:基于redis cluster的横向扩展,可以实现分布式集群,大幅提升性能和数据安全性
1.4.6 Redis和memcached比较
1、Redis不仅仅支持简单的kN类型的数据,同时还提供list, set, zset, hash等数据结构的存储。
2、Redis支持master-slave(主一从模式应用)
3、Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
4、Redis单个value存储string的最大限制是512MB, memcached只能保存1MB的数据
5、redis是单核,memcached是多核
由于redis只能使用单核,而memcached可以使用多核,所以在比较上,平均每一个校上redis在储存小数据时比memcached性能更高。而却100K以上数据中,memcached性能要高于redis,虽然redis最近也在储存大数据的性能上进行优化,但是比起memcached还是有点逊色。结论是无论你使用那个,每秒处理请求的次数都不会成为瓶颈。
你需要关注内存使用率。对于key-Vlaue这样简单的数据储存,memcached的内存使用率更高,如果采用hash结构,redis的内存使用率会更高,当然这都依赖于具体的应用场景
二、部署redis
redis分为Linux版本和Windows版本,Windows 安装包是某位民间“大神”根据 Redis 源码改造的,并非 Redis 官方网站提供。
2.1 安装Windows版本
github下载地址:https://github.com/tporadowski/redis/releases
在 Windows 系统下安装 Redis 要比 Linux 系统安装稍微复杂一些,本节详细介绍如何在 Windows 系统上如何安装 Redis。
打开上述的下载链接,Redis 支持 32 位和 64 位的 Window 系统,大家根据个人情况自行下载,如图 1 所示:
 图1:Redis 安装
图1:Redis 安装
下载完成后,打开相应的文件夹,您会看到如下图所示的文件目录:
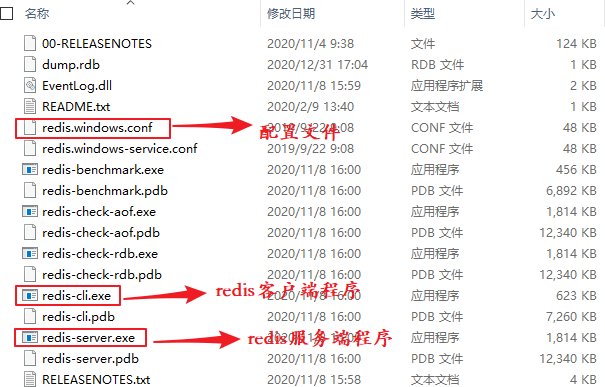 图2:Window 安装 Redis
图2:Window 安装 Redis
2.1.1 创建Redis临时服务
2.1.1.1 启动服务端程序
如上图所示,双击 Redis 服务端启动程序 redis-server.exe,您会看到以下界面:
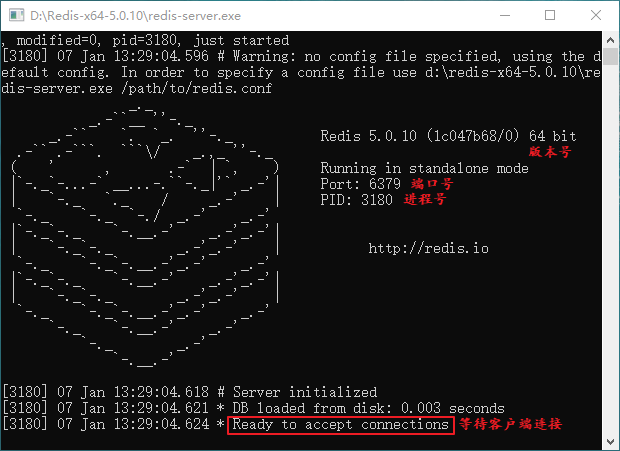 图3:启动 Redis 服务端程序
图3:启动 Redis 服务端程序
上图中显示一些 Redis 的相关信息,比如 Redis 的版本号以及默认端口号(6379)。注意,为了实现后续操作,请您保持服务端开启状态,否则客户端无法正常工作。
2.1.1.2 启动客户端程序
启动服务端后,双击客户端启动程序 redis-cli.exe,得到如下界面:
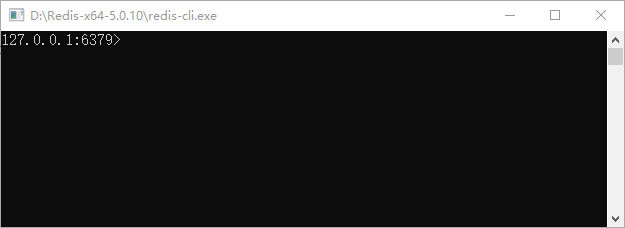 图4:Redis客户端启动
图4:Redis客户端启动
得到如上界面,说明 Redis 本地客户端与服务端连接成功。
2.1.2 命令创建Redis服务
上述方式虽然简单快捷,但是显然不是程序员的操作,下面介绍,通过命令启动 Redis 服务端,并将 Redis 服务添加到 Windows 资源管理器,实现开机后自动启动。
2.1.2.1 注册Redis服务
通过 CMD 命令行工具进入 Redis 安装目录,将 Redis 服务注册到 Windows 服务中,执行以下命令:
redis-server.exe --service-install redis.windows.conf --loglevel verbose
执行完后,得到以下输出,说明注册成功。
[3568] 31 May 16:25:12.908 # Granting read/write access to 'NT AUTHORITY\NetworkService' on: "E:\Redis-x64-5.0.14.1" "E:\Redis-x64-5.0.14.1\"
[3568] 31 May 16:25:12.908 # Redis successfully installed as a service.
2.1.2.2 启动Redis服务
执行以下命令启动 Redis 服务,命令如下:
redis-server --service-start
如下图所示:
 图5:命令启动 Redis 服务
图5:命令启动 Redis 服务
注意:此时 Redis 已经被添加到 Windows 服务中,因此不会再显示 Redis 服务端的相应的信息,如下图所示:
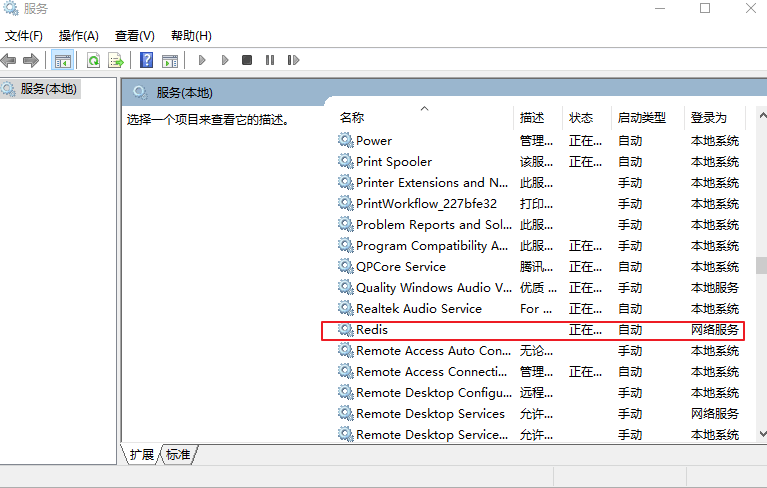 图6:Windows 服务管理界面
图6:Windows 服务管理界面
2.1.3 启动Redis客户端
在 CMD 命令行输出 redis-cli 命令启动客户端,如下所示:
 图7:启动 Redis 客户端
图7:启动 Redis 客户端
2.1.4 检查是否连接成功
测试客户端和服务端是否成功连接。输出 PING命令,若返回 PONG则证明成功连接。如下所示:
 图8:测试客户端是否连接
图8:测试客户端是否连接
通过上面的操作,我们完成了 Redis 的安装。当然,您也可以将 Redis 加入到环境变量中,如下所示:
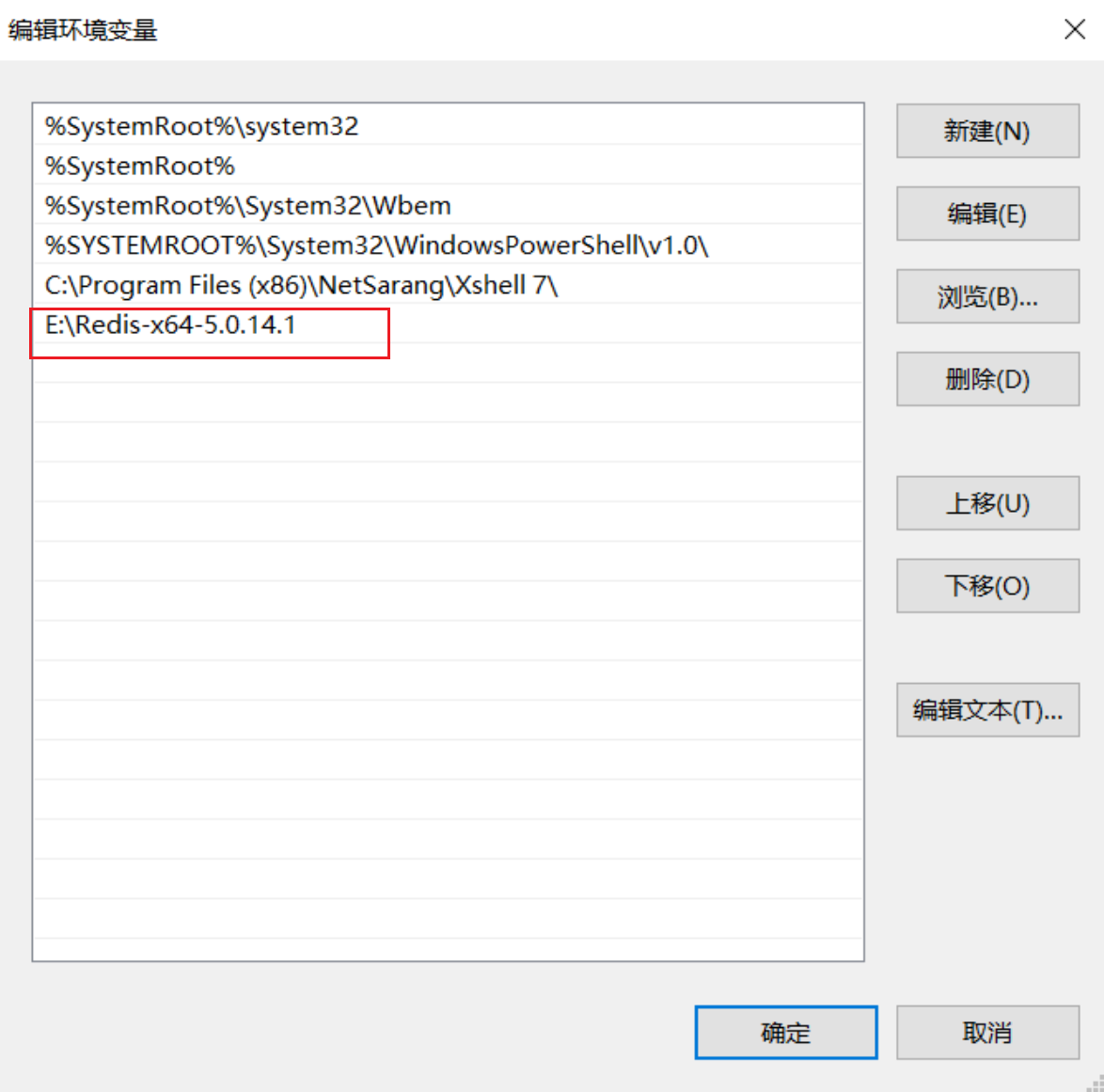 图9:环境变量配置
图9:环境变量配置
注意:根据自己的安装路径添加环境变量。
总结
下面对安装过程中涉及到的命令进行总结,主要包括以下命令:
安装服务:redis-server --service-install
卸载服务:redis-server --service-uninstall
开启服务:redis-server --service-start
停止服务:redis-server --service-stop
服务端启动时重命名:redis-server --service-start --service-name Redis1
2.2 安装Linux版本
2.2.1 yum 安装 Redis
CentOS系统yum仓库自带redis 版本
- CentOS7:redis 3.2.12 (epel)
- CentOS8:redis 5.0.3 (base)
2.2.2 源码包安装
2.2.2.1 解压redis压缩包
[root@localhost redis-6.0.16]# yum -y install gcc
[root@redis ~]# tar zxvf redis-6.0.16.tar.gz -C /usr/local/src/
[root@redis redis-6.0.16]# make PREFIX=/usr/local/redis install
cd /usr/local/src/ && tar xf /usr/local/src/redis-6.0.16.tar.gz && cd /usr/local/src/redis-6.0.16 && make PREFIX=/usr/local/redis install
安装过程中如果存在如下的报错,则是因为默认的gcc的版本太低导致的,可以使用如下的办法解决
[root@redis redis-6.0.16]#yum -y install centos-release-scl
[root@redis redis-6.0.16]#yum -y install devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutils
[root@redis redis-6.0.16]#scl enable devtoolset-9 bash
2.2.2.2 查看安装的执行文件
[root@redis bin]# cd /usr/local/redis/bin/
[root@redis bin]# ls
redis-benchmark redis-check-aof redis-check-rdb redis-cli redis-sentinel redis-server
2.2.2.3 配置服务启动文件
vim /usr/lib/systemd/system/redis.service
cat >>/usr/lib/systemd/system/redis.service<<EOF
[Unit]
Description=Redis persistent key-value database
After=network.target
[Service]
ExecStart=/usr/local/redis/bin/redis-server /usr/local/redis-6.0.16/redis.conf
ExecReload=/bin/kill -s HUP $MAINPID
ExecStop=/bin/kill -s QUIT $MAINPID
Type=notifyUser=redis
Group=redis
RuntimeDirectory=redis
RuntimeDirectoryMode=0755
[Install]
WantedBy=multi-user.target
EOF
*******************************************************************************************************************************
[Unit]
Description=Redis persistent key-value database
After=network.target
[Service]
Type=forking
PIDFile=/var/run/redis_6379.pid
ExecStart=/usr/local/redis/bin/redis-server /usr/local/redis-6.0.16/redis.conf
#ExecStop=/usr/libexec/redis-shutdown
ExecReload=/bin/kill -s HUP $MAINPID
ExecStop=/bin/kill -s QUIT $MAINPID
#Type=notifyUser=redis
Group=redis
RuntimeDirectory=redis
RuntimeDirectoryMode=0755
[Install]
WantedBy=multi-user.target
[root@redis bin]# useradd -r redis -s /sbin/nologin
[root@redis bin]# systemctl daemon-reload
2.2.2.4 启动redis
前台启动redis
[root@redis bin]# cd /usr/local/redis/bin/
[root@redis bin]# ./redis-server ##前台启动命令
13703:C 29 Oct 2022 13:57:18.508 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
13703:C 29 Oct 2022 13:57:18.508 # Redis version=6.0.16, bits=64, commit=00000000, modified=0, pid=13703, just started
13703:C 29 Oct 2022 13:57:18.508 # Warning: no config file specified, using the default config. In order to specify a config file use ./redis-server /path/to/redis.conf
13703:M 29 Oct 2022 13:57:18.509 * Increased maximum number of open files to 10032 (it was originally set to 1024).
_._
_.-``__ ''-._
_.-`` `. `_. ''-._ Redis 6.0.16 (00000000/0) 64 bit
.-`` .-```. ```\/ _.,_ ''-._
( ' , .-` | `, ) Running in standalone mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 6379
| `-._ `._ / _.-' | PID: 13703
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | http:#redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'
13703:M 29 Oct 2022 13:57:18.509 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
13703:M 29 Oct 2022 13:57:18.509 # Server initialized
13703:M 29 Oct 2022 13:57:18.509 # WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect.
13703:M 29 Oct 2022 13:57:18.509 # WARNING you have Transparent Huge Pages (THP) support enabled in your kernel. This will create latency and memory usage issues with Redis. To fix this issue run the command 'echo madvise > /sys/kernel/mm/transparent_hugepage/enabled' as root, and add it to your /etc/rc.local in order to retain the setting after a reboot. Redismust be restarted after THP is disabled (set to 'madvise' or 'never').
13703:M 29 Oct 2022 13:57:18.509 * Ready to accept connections
后台启动redis
[root@redis bin]# systemctl start redis
[root@redis bin]# ps -ef |grep redis
root 13684 1 0 13:52 ? 00:00:00 /usr/local/redis/bin/redis-server 127.0.0.1:6379
root 13689 13124 0 13:52 pts/1 00:00:00 grep --color=auto redis
2.2.3 redis的基本操作
2.2.3.1 redis的配置文件
[root@redis bin]# vim /usr/local/src/redis-6.0.16/redis.conf
daemonize no #表示 redis 并不会运行成为一个守护进程,如果需要运行成为一个守护进程,则把 no,改为 yes 即可,如果使用服务脚本启动,即使 daemonize 为 no,也会运行为一个守护进程
port 6379 #监听端口:6379/tcp
tcp-backlog 511 #指定 tcp-backlog 的长度
说明:任何的 tcp 服务都有可能使用到 tcp-backlog 功能,backlog 是一个等待队列,比如:redis 的并发很高时,redis 运行不过来时,就连接本地缓存等队列都满了以后,就会使用额外的存储地方,把新来的请求暂存下来,而这个位置则称为 backlog
bind 127.0.0.1 #监听的地址,默认监听在 127.0.0.1 地址上,可以指定为 0.0.0.0 地址,或某个特定的地址,或可以指定多个,使用空格分隔即可#
protected-mode yes # redis3.2 之后加入的新特性,在没有设置bind IP和密码的时候,redis只允许访问127.0.0.1:6379,可以远程连接,但当访问将提示警告信息并拒绝远程访问
unixsocket /tmp/redis.sock #指定使用 sock 文件通信及 sock 文件位置,如果服务端和客户都在同一台主机上,建议打开此项,基于 sock 方式通信可以直接在内存中交换,数据不用再经过 TCP/TP协议栈进行封装、拆封
unixsocketperm 700 #定义 sock 文件的访问权限
timeout 0 #表示当客户端连接成功后,空闲(非活跃、或没有任何数据交互)多长时间则连接超时,0 表示不启用此功能
tcp-keepalive 0 #定义是否启用 tcp-keepalive 功能
loglevel notice #定义日志级别
logfile /var/log/redis/redis.log #定义日志文件
databases 16 #定义 redis 默认有多少个 databases,但是在分布式中,只能使用一个,默认是0号数据库
#### SNAPSHOTTING #### #定义 RDB 的持久化相关
save <seconds> <changes> #使用 save 指令,并指定每隔多少秒,如果发生多大变化,进
行存储
示例:
save 900 1 #表示在 900 秒(15 分钟内),如果至少有 1 个键发生改变,则做一次快照(持
久化)
save 300 10 #表示在 300 秒(5 分钟内),如果至少有 10 个键发生改变,则做一次快照(持
久化)
save 60 10000 #表示在 60 秒(1 分钟内),如果至少有 10000 个键发生改变,则做一次快照
(持久化)
save "" #如果 redis 中的数据不需做持久化,只是作为缓存,则可以使用此方式关闭持久化
功能
stop-writes-on-bgsave-error yes #后台存储错误停止写
rdbcompression yes #存储至本地数据库是(持久化到rdb)中是否压缩数据,默认是yes
dbfilename dump.rdb #本地化持久数据库文件名,默认是dump.rdb
######## REPLICATION ####### #配置主从相关
# slaveof <masterip> <masterport> #此项不启用时,则为主,如果启动则为从,但是需
要指明主服务器的 IP,端口
# masterauth <master-password> #如果主服务设置了密码认证,那么从的则需要启用此项
并指明主的认证密码
slave-serve-stale-data yes #配置slave实例是否接受写,写slave对存储短暂数据是有用得,默认是yes.
slave-read-only yes #定义从服务对主服务是否为只读(仅复制)
# repl-ping-slave-period 10 #从库向主库会按照一个将时间发送ping,默认是10S
# repl-timeout 60 #设置主库批量数据传输时间或者Ping恢复间隔时间,默认是60S,注意这个值一定要大于repl-ping-slave-period
repl-disable-tcp-nodelay no #如果选择“yes”,redis会使用一个较小的的数字TCP数据表和更小的带宽将数据发送到slave,这可能导致数据发送到slave端会有延时,如果选择“no",则发送数据到slave的延时更小。
# repl-backlog-size 1mb #设置复制的后台日志大小,日志设置的越大,slave断开连接后以及以后可能执行部分复制化的时间就越长
slave-priority 100 #如果master异常,那么会在多个slave中选择优先值最小的一个slave来提升为master,优先值为0,表示不能提升为Master
################################ SECURITY #######################################
# requirepass foobared #定义连接redis后进行操作,需要使用密码验证
############################## LIMITS ############################# #定义与连接和资源限制相关的配置
# maxclients 10000 #定义最大连接限制(并发数)
# maxmemory <bytes> #定义使用主机上的最大内存,默认此项关闭,表示最大将使用主机上的最大可用内存
当内存达到最大值是,内存中键值的删除策略
# volatile-lru -> 利用LRU算法移除设置过期时间的key
# allkeys-lru -> 利用LRU算法来移除任何key
# volatile-lfu -> 从已设置过期时间的key中挑选最不经常使用的数据淘汰
# allkeys-lfu -> 从所有的Key中来移除使用频率最低的key
# volatile-random -> 移除设置过期时间的随机key
# allkeys-random -> 随机移除任何的key
# volatile-ttl -> 移除即将过期的key
# noeviction -> 如果对于上面的Key没有key可以删除,在写数据的时候返回一个错误。
############################## APPEND ONLY MODE ####### #定义 AOF 的持久化功能相关配置,一旦有某
一个键发生变化,将修改键的命令附加到命令列表的文件中,类似于 MySQL 二进制日志
appendonly no #定义是否开启此功能,no 表示关闭,yes 表示开启
说明:RDB 和 AOF 两种持久功能可以同时启用,两者不影
appendfilename "appendonly.aof" #AOF持久化的名字
键同步AOF中的策略
# appendfsync always #每次有键值有变化就进行同步。速度最慢
appendfsync everysec #每秒钟同步一次 ,速度快
# appendfsync no #不同步,速度最快,让系统决定同步策略
建议如果不知道设置成哪种,可以选择“everysec”,在数据安全性和同步速度是最平衡的。
no-appendfsync-on-rewrite no #后台执行(RDB的save | aof重写)时appendfsync设为no。
(当AOF 的appendfsync配置为 everysec 或 always ,并且后台运行着RDB的save或者AOF重写时,(由于save和rewrite会)消耗大量的磁盘性能。在某些Linux配置下,aof同步到磁盘执行 fsync() 将被阻塞很长时间。
注意:这个问题目前还没有解决办法。因为即使在不同的线程中执行fsync,也会阻塞同步 write() 调用。
为了减轻这个问题,可以使用 no-appendfsync-on-rewrite 选项防止执行BGSAVE或BGREWRITEAOF时,在主进程中调用fsync()。这意味着当有另一个子进程执行BGSAVE或BGREWRITEAOF 时,磁盘同步策略相当于 appendfsync no。在最坏的情况下(使用默认的Linux设置)可能会丢失最多30秒的日志。
如果你有延迟问题可以将该项设置为“yes”。否则,从数据完整性的角度看,使用“no”更安全
auto-aof-rewrite-percentage 100 #如果是0代表,这个值是用于防止文件即使很小但是增长幅度很大也进行重写
auto-aof-rewrite-min-size 64mb #指定AOF文件大小
aof-load-truncated yes #指定当发生AOF文件末尾截断时,加载文件还是报错退出
aof-use-rdb-preamble no #开启混合持久化,更快的AOF重写和启动时数据恢复,如果是No,则不开启
2.2.3.2 连接redis
Redis属于轻量级NoSQL数据库,没有用户账号和用户权限控制,直接通过密码登录Redis数据拥有最高操作权限,默认安装Redis是无密码直接连接
安全检查命令:
| 命令 | 说明 |
|---|---|
| AUTH password | 验证密码是否正确 |
| ECHO message | 打印字符串 |
| PING | 查看服务是否运行正常 |
| QUIT | 关闭当前连接 |
| SELECT index | 切换到指定的数据库 |
方法1:使用telnet连接
[root@redis bin]# telnet 127.0.0.1 6379
info ##表示获取redis的服务器的信息
set a 100 ##表示设置一个k-v的值,键是a,值是100
get a ##获取键a的值
方法2:使用redis自带客户端连接
[root@redis bin]# redis-cli -h
选项:-h <hostname> 指定主机 IP
-p <port> 指定端口 socket 文件进行通信
-s <socket> 指定 socket 文件,如果客户端口和服务端都在同一台主机,可以指定 socket 文
件进行通信
-a <password> 指定认证密码
-r <repeat> 连接成功后指定运行的命令 N 次
-i <interval> 连接成功后每个命令执行完成等待时间,使用-i 选项指定
-n <db>
[root@redis bin]# redis-cli -h localhost ##默认登录不需要密码
localhost:6379> set b 200
OK
localhost:6379> get b
"200"
localhost:6379> info
# Server
redis_version:6.0.16
redis_git_sha1:00000000
redis_git_dirty:0
redis_build_id:b63746939d966c35
redis_mode:standalone
os:Linux 3.10.0-1160.76.1.el7.x86_64 x86_64
arch_bits:64
multiplexing_api:epoll
atomicvar_api:atomic-builtin
gcc_version:9.3.1
process_id:13714
run_id:63702cfd6128b73f1471214cb31aa3e24b9c2822
tcp_port:6379
uptime_in_seconds:758
uptime_in_days:0
hz:10
configured_hz:10
lru_clock:6079571
executable:/usr/local/redis/bin/redis-server
config_file:/usr/local/src/redis-6.0.16/redis.conf
io_threads_active:0
.......
localhost:6379> select 1 ##表示切换到 1 号库中,默认为 0 号库,共 16 个,0-15
OK
localhost:6379[1]>
localhost:6379[1]> exit ##exit,退出登录
客户端常用命令:
| 命令 | 说明 |
|---|---|
| CLIENT LIST | 以列表的形式返回所有连接到 Redis 服务器的客户端。 |
| CLIENT SETNAME | 设置当前连接的名称。 |
| CLIENT GETNAME | 获取通过 CLIENT SETNAME 命令设置的服务名称。 |
| CLIENT PAUSE | 挂起客户端连接,将所有客户端挂起指定的时间(以毫秒为计算)。 |
| CLIENT KILL | 关闭客户端连接。 |
| CLIENT ID | 返回当前客户端 ID。 |
| CLIENT REPLY | 控制发送到当前连接的回复,可选值包括 on|off|skip。 |
方法3: python 连接Redis
python 多种开发库可以支持连接redis,官方推荐使用redis-py 连接 redis
redis-py模块的GitHub地址:https:#github.com/andymccurdy/redis-py
#安装python3和redis-py模块
yum -y install python3 python3-redis
#python连接redis脚本,(注意文件名不要为redis,会和redis模块名称冲突)
[root@centos7 ~ ]# vim py-redis.py
#!/bin/env python3
import redis
#import time
pool = redis.ConnectionPool(host="127.0.0.1",port=6379,password="")
r = redis.Redis(connection_pool=pool)
for i in range(1,101):
r.set("k%d" % i,"v%d" % i)
# time.sleep(1)
data=r.get("k%d" % i)
print(data)
[root@centos7 ~ ]# python3 py-redis.py
b'v1'
b'v2'
......
b'v99'
b'v100'
#查看redis的键值情况
[root@centos7 ~ ]# redis-cli -p 6379
127.0.0.1:6379> info
......
# Keyspace
db0:keys=201,expires=0,avg_ttl=0
方法4: 图形工具连接


2.2.4 key的遵循规则
1)可以使用 ASCII 字符
2)键的长度不要过长,键的长度越长则消耗的空间越多,也不要太短,不好理解其含义
3)在同一个库中(名称空间),键的名称不得重复,如果复制键的名称,实际上是修改键中的值
4)在不同的库中(名称空间),键的名称可以重复
5)键可以实现自动过期
2.2.4.1 Redis键(key)命令
1)keys * #查看当前库所有key (匹配:keys *1)
2)exists key #判断某个key是否存在
3)type key #查看你的key是什么类型
4)del key #删除指定的key数据
5)unlink key #根据value选择非阻塞删除,仅将keys从keyspace元数据中删除,真正的删除会在后续异步操作。
6)expire key 10 #10秒钟:为给定的key设置过期时间
7)ttl key #查看还有多少秒过期,-1表示永不过期,-2表示已过期
8)select #切换数据库
9)dbsize #查看当前数据库的key的数量
10)flushdb #清空当前库
11)flushall #清空全部库
12)shutdown #关闭redis
默认16个数据库,类似数组下标从0开始,初始默认使用0号库
2.2.4.2 演示案例
localhost:6379> keys * ##查看所有的key
1) "a"
localhost:6379>
localhost:6379> exists a ##检查是否存在a这个key
(integer) 1
localhost:6379> exists a b ##同时检查多个key
(integer) 2
localhost:6379> type a ##查看key的类型
string
localhost:6379> del b ##删除key
(integer) 1
localhost:6379> unlink a ##根据value选择非阻塞删除,仅将keys从keyspace元数据中删除,真正的删除会在后续异步操作
(integer) 1
localhost:6379> get a
(nil)
localhost:6379> set a 100
OK
localhost:6379> expire a 1 ##设置a键的过期时间,默认是s
(integer) 1
localhost:6379> ttl a ##查看键的过期时间,-2代表已经过期,-1表示永不过期
(integer) -2
localhost:6379> rename a aaa ##将键重新重命名
OK
localhost:6379>
localhost:6379> select 1 ##选择数据库,默认是0
OK
localhost:6379[1]> dbsize ##查看当前库的键数量
(integer) 0
localhost:6379[1]> set name zhangsan
OK
localhost:6379[1]> dbsize
(integer) 1
localhost:6379[1]> flushdb ## 清空数据库
OK
localhost:6379> flushall ##清空所有数据库
·
OK
2.2.5 Redis数据类型
2.2.5.1 Strings
string是redis的基本类型,它可以存储任何类型的数据,单个key的最大空间是512M
127.0.0.1:6379> help set
SET key value [EX seconds] [PX milliseconds] [NX|XX] #命令 键 值 [EX 过期时间,单位
秒]
summary: Set the string value of a key
since: 1.0.0
group: string
NX:如果一个键不存在,才创建并设定值,否则不允许设定
XX:如果一个键存在则设置建的值,如果不存在则不创建并不设置其值
案例演示:
localhost:6379> set hubei wuhan ##设置一个键为湖北,值为武汉
OK
localhost:6379> get hubei ##获取hubei这个键的值
"wuhan"
localhost:6379> set wuhan 123 NX ##设置一个键为wuhan,值为123,不存在时可以创建的
OK
localhost:6379> set wuhan 123 NX ##设置一个键为wuhan,值为123,键存在时不可以创建,返回一个nil空
(nil)
localhost:6379> set wuhan 123 XX ##设置一个键为user,值是123,如果键键存在则设置建的值
OK
localhost:6379> set user 123 XX ##设置一个键为user,值是123,如果不存在则不创建并不设置其值
(nil)
localhost:6379> set abc 123 EX 60 ##设置一个键为abc,值为123,过期时间为60s
OK
localhost:6379> get abc ##获取abc的值,已经超时被清除
(nil)
localhost:6379[1]> mset name zhangsan age 20 ##同时设置多个k-v
OK
localhost:6379[1]> mget name age ##同时获取多个
1) "zhangsan"
2) "20"
localhost:6379[1]> INCR age ##增加1
(integer) 21
localhost:6379[1]> DECR age ##减少1
(integer) 20
localhost:6379[1]> INCRBY age 10 ##增加10
(integer) 30
localhost:6379[1]> DECRBY age 15 ##减少15
(integer) 15
localhost:6379> append hubei xianning ##添加键中的值(在原有键中附加值的内容):
(integer) 13
localhost:6379> get hubei
"wuhanxianning"
localhost:6379> substr hubei 5 12 ##截取字符串,从下标0开始
"xianning"
localhost:6379>
localhost:6379> substr hubei 0 -1 ##截取所有的字符串
"wuhanxianning"
localhost:6379>
localhost:6379> strlen hubei ##查看字符串长度
(integer) 13
注:incr 命令只能对整数使用
127.0.0.1:6379> del fda 删除键:
(integer) 1
2.2.5.2 list
Redis中的List其实就是双端链表,我们可以使用RPUSH和LPUSH从链头和链尾添加和删除元素
list既可以做队列,也可以做栈
同一端进出,先进后出,叫栈(羽毛球)
一端进,另一端出,先进先出,叫队列(排队打饭)
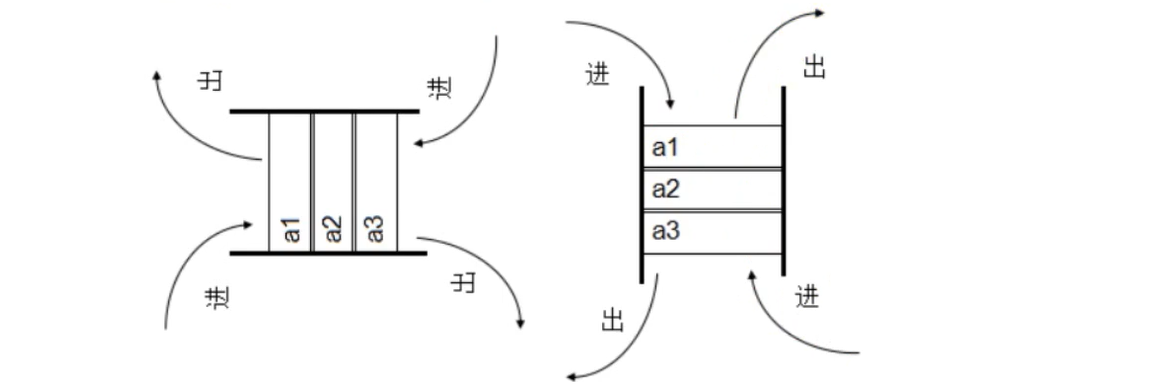
键指向一个列表,而列表可以理解为是一个字符串的容器,列表是有众多元素组成的集合,可以在键所指向的列表中附加一个值
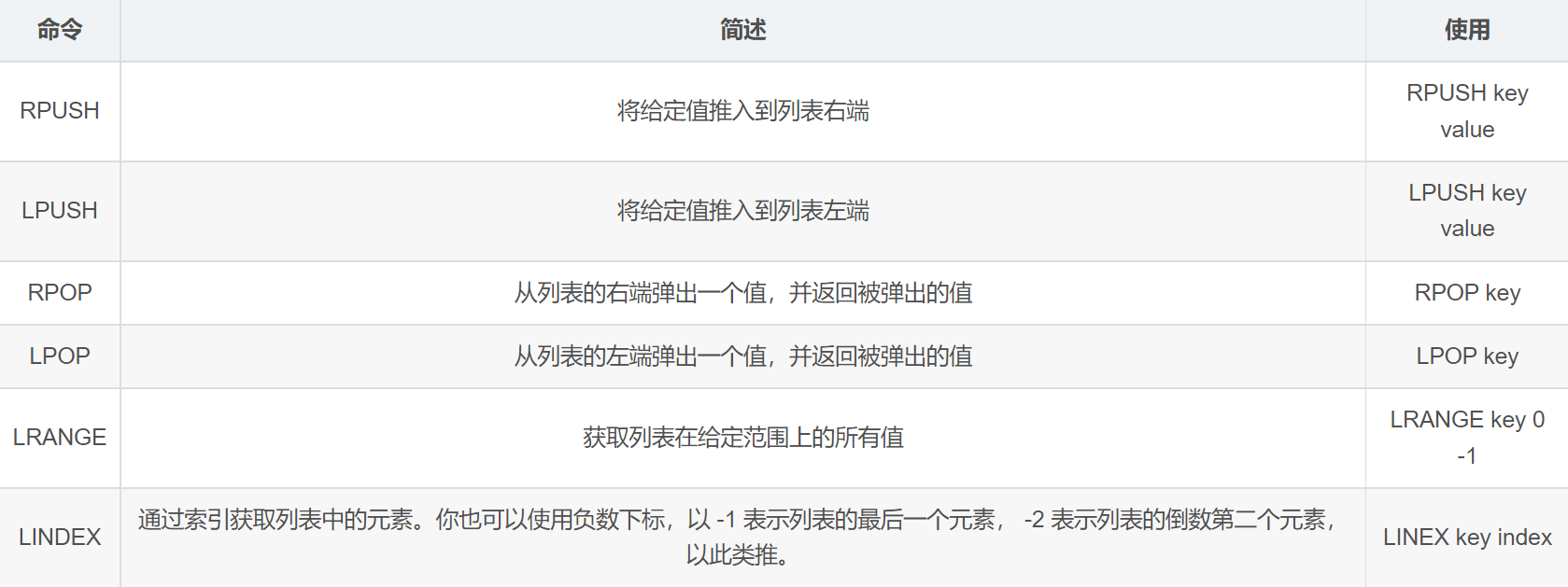
Lists 的常用命令:
LPUSH #在键所指向的列表前面插入一个值(左边加入)
RPUSH #在键所指向的列表后面附加一个值(右边加入)
LPOP #在键所指向的列表前面弹出一个值(左边弹出)
RPOP #在键所指向的列表后面弹出一个值(右边弹出)
LINDEX #根据索引获取值,指明索引位置进行获取对应的值
LSET #用于修改指定索引的值为指定的值
案例:老师想登记班里谁先到班,谁最后到班?
localhost:6379> lpush name zhangsan ##往列表中推入学生名字
(integer) 1
localhost:6379> lpush name lisi ##往列表中推入学生名字
(integer) 2
localhost:6379> lpush name wangwu ##往列表中推入学生名字
(integer) 3
localhost:6379> LPOP name ##栈操作
"wangwu"
localhost:6379> rpop name ##队列操作
"zhangsan"
localhost:6379> llen name ##查看队列的长度,wangwu和zhangsan已经被推出去了
(integer) 1
localhost:6379>
localhost:6379> rpush name wangwu ##重新在列表尾部推送2个名字
(integer) 2
localhost:6379> rpush name zhangsan
(integer) 3
localhost:6379> LRANGE name 0 -1 ##查看列表的内容
1) "lisi"
2) "wangwu"
3) "zhangsan"
localhost:6379>
localhost:6379> LRANGE name -1 -1 ##取出最后进班的人
1) "zhangsan"
localhost:6379>
localhost:6379> lindex name 1 ##根据下标来取值
"wangwu"
localhost:6379>
localhost:6379> type name ##查看key的类型
list
2.2.5.3 set
Redis 的 Set 是 String 类型的无序集合,集合成员是不可重复的
set的最大可以有2的32次方-1个元素
关于set集合类型除了基本的添加删除操作,其他常用的操作还包含集合的取 并集(union), 交集(intersection). 差集(difference)。通过这些操作可以很容易的实现sns中的好友推荐功能。
命令使用:
命令 简述 使用
SADD 向集合添加一个或多个成员 SADD key value
SCARD 获取集合的成员数 SCARD key
SMEMBER 返回集合中的所有成员 SMEMBER key member
SISMEMBER 判断 member 元素是否是集合 key 的成员 SISMEMBER key member
# ===================================================
# sadd 将一个或多个成员元素加入到集合中,不能重复
# smembers 返回集合中的所有的成员。
# sismember 命令判断成员元素是否是集合的成员。
# ===================================================
127.0.0.1:6379> sadd myset "hello"
(integer) 1
127.0.0.1:6379> sadd myset "kuangshen"
(integer) 1
127.0.0.1:6379> sadd myset "kuangshen"
(integer) 0
127.0.0.1:6379> SMEMBERS myset
1) "kuangshen"
2) "hello"
127.0.0.1:6379> SISMEMBER myset "hello"
(integer) 1
127.0.0.1:6379> SISMEMBER myset "world"
(integer) 0
# ===================================================
# scard,获取集合里面的元素个数
# ===================================================
127.0.0.1:6379> scard myset
(integer) 2
# ===================================================
# srem key value 用于移除集合中的一个或多个成员元素
# ===================================================
127.0.0.1:6379> srem myset "kuangshen"
(integer) 1
127.0.0.1:6379> SMEMBERS myset
1) "hello"
# ===================================================
# srandmember key 命令用于返回集合中的一个随机元素。
# ===================================================
127.0.0.1:6379> SMEMBERS myset
1) "kuangshen"
2) "world"
3) "hello"
127.0.0.1:6379> SRANDMEMBER myset
"hello"
127.0.0.1:6379> SRANDMEMBER myset 2
1) "world"
2) "kuangshen"
127.0.0.1:6379> SRANDMEMBER myset 2
1) "kuangshen"
2) "hello"
# ===================================================
# spop key 用于移除集合中的指定 key 的一个或多个随机元素
# ===================================================
127.0.0.1:6379> SMEMBERS myset
1) "kuangshen"
2) "world"
3) "hello"
127.0.0.1:6379> spop myset
"world"
127.0.0.1:6379> spop myset
"kuangshen"
127.0.0.1:6379> spop myset
"hello"
# ===================================================
# smove SOURCE DESTINATION MEMBER
# 将指定成员 member 元素从 source 集合移动到 destination 集合。
# ===================================================
127.0.0.1:6379> sadd myset "hello"
(integer) 1
127.0.0.1:6379> sadd myset "world"
(integer) 1
127.0.0.1:6379> sadd myset "kuangshen"
(integer) 1
127.0.0.1:6379> sadd myset2 "set2"
(integer) 1
127.0.0.1:6379> smove myset myset2 "kuangshen"
(integer) 1
127.0.0.1:6379> SMEMBERS myset
1) "world"
2) "hello"
127.0.0.1:6379> SMEMBERS myset2
1) "kuangshen"
2) "set2"
# ===================================================
- 数字集合类
- 差集: sdiff
- 交集: sinter
- 并集: sunion
# ===================================================
localhost:6379> sadd key1 zhangsan lisi wangwu zhaoliu xiaohua
(integer) 5
localhost:6379> sadd key2 zhangsan maqi zhaoliu liusan qiansi
(integer) 5
localhost:6379> SDIFF key1 key2 ##差集
1) "wangwu"
2) "xiaohua"
3) "lisi"
localhost:6379> SINTER key1 key2 ##交集
1) "zhangsan"
2) "zhaoliu"
localhost:6379> SUNION key1 key2 ##并集
1) "qiansi"
2) "maqi"
3) "wangwu"
4) "zhangsan"
5) "zhaoliu"
6) "liusan"
7) "lisi"
8) "xiaohua"
localhost:6379>
2.2.5.4 zset
Redis 有序集合和集合一样基本一致元素不能重复
使用场景:
排行榜:有序集合经典使用场景。例如应用市场上的收集APP的排名。
成绩排行:比如一个存储全班同学成绩的sorted set,其集合value可以是同学的学号,而score就可以是其考试得分, 形成了按成绩排序。
权重分配:可以用sorted set来做带权重的队列,比如普通消息的score为1,重要消息的score为2,然后工作线程可以选择按score的倒序来获取工作任务。让重要的任务优先执行。
需求:统计一下应用市场上APP的排名
key:appTop
id score name
1 2 wechat
2 1 QQ
3 4 toutiao
4 7 taobao
5 6 jd
6 8 kugou
localhost:6379> zadd appTop 2 wechat 1 QQ 4 toutiao 7 taobao 6 jd 8 kugou
localhost:6379> ZRANGE appTop 0 -1 ##排序,从小到大
1) "QQ"
2) "wechat"
3) "toutiao"
4) "jd"
5) "taobao"
6) "kugou"
localhost:6379>
localhost:6379> ZREVRANGE appTop 0 -1 ##排序,从大到小
1) "kugou"
2) "taobao"
3) "jd"
4) "toutiao"
5) "wechat"
6) "QQ"
localhost:6379>
localhost:6379> zscore appTop kugou ##获取kugou和wechat的score
"8"
localhost:6379> zscore appTop wechat
"2"
localhost:6379> ZINCRBY appTop -2 wechat ##修改wechat的权重,-2代表权重减少2
"0"
localhost:6379> ZRANGE appTop 0 -1 ##再次查看wechat变成了排名第一
1) "wechat"
2) "QQ"
3) "toutiao"
4) "jd"
5) "taobao"
6) "kugou"
localhost:6379>
2.2.5.5 hash
Redis hash 是一个 string 类型的 field(字段) 和 value(属性) 的映射表,hash 特别适合用于存储对象。
一个hash可以存多个key-value,类似一个对象的多个字段和属性
使用场景:
缓存: 能直观,相比string更节省空间,的维护缓存信息,如用户信息,视频信息等。
命令使用
命令 简述 使用
HSET 添加键值对 HSET hash-key sub-key1 value1
HGET 获取指定散列键的值 HGET hash-key key1
HGETALL 获取散列中包含的所有键值对 HGETALL hash-key
HDEL 如果给定键存在于散列中,那么就移除这个键 HDEL hash-key sub-key1
# ===================================================
# hset、hget 命令用于为哈希表中的字段赋值 。
# hmset、hmget 同时将多个field-value对设置到哈希表中。会覆盖哈希表中已存在的字段。
# hgetall 用于返回哈希表中,所有的字段和值。
# hdel 用于删除哈希表 key 中的一个或多个指定字段
# ===================================================
127.0.0.1:6379> hset myhash field1 "huangkaiyu"
(integer) 1
127.0.0.1:6379> hget myhash field1
"huangkaiyu"
127.0.0.1:6379> HMSET myhash field1 "Hello" field2 "World"
OK
127.0.0.1:6379> HGET myhash field1
"Hello"
127.0.0.1:6379> HGET myhash field2
"World"
127.0.0.1:6379> hgetall myhash
1) "field1"
2) "Hello"
3) "field2"
4) "World"
127.0.0.1:6379> HDEL myhash field1
(integer) 1
127.0.0.1:6379> hgetall myhash
1) "field2"
2) "World"
# ===================================================
# hlen 获取哈希表中字段的数量。
# ===================================================
127.0.0.1:6379> hlen myhash
(integer) 1
127.0.0.1:6379> HMSET myhash field1 "Hello" field2 "World"
OK
127.0.0.1:6379> hlen myhash
(integer) 2
# ===================================================
# hexists 查看哈希表的指定字段是否存在。
# ===================================================
127.0.0.1:6379> hexists myhash field1
(integer) 1
127.0.0.1:6379> hexists myhash field3
(integer) 0
# ===================================================
# hkeys 获取哈希表中的所有域(field)。
# hvals 返回哈希表所有域(field)的值。
# ===================================================
127.0.0.1:6379> HKEYS myhash
1) "field2"
2) "field1"
127.0.0.1:6379> HVALS myhash
1) "World"
2) "Hello"
# ===================================================
# hincrby 为哈希表中的字段值加上指定增量值。
# ===================================================
127.0.0.1:6379> hset myhash field 5
(integer) 1
127.0.0.1:6379> HINCRBY myhash field 1
(integer) 6
127.0.0.1:6379> HINCRBY myhash field -1
(integer) 5
127.0.0.1:6379> HINCRBY myhash field -10
(integer) -5
# ===================================================
# hsetnx 为哈希表中不存在的的字段赋值 。
# ===================================================
127.0.0.1:6379> HSETNX myhash field1 "hello"
(integer) 1 # 设置成功,返回 1 。
127.0.0.1:6379> HSETNX myhash field1 "world"
(integer) 0 # 如果给定字段已经存在,返回 0 。
127.0.0.1:6379> HGET myhash field1
"hello"
2.2.5.6 HyperLoglog
HyperLoglog 是 Redis 重要的数据类型之一,它非常适用于海量数据的计算、统计,其特点是占用空间小,计算速度快。
HyperLoglog 采用了一种基数估计算法,因此,最终得到的结果会存在一定范围的误差(标准误差为 0.81%)。每个 HyperLogLog key 只占用 12 KB 内存,所以理论上可以存储大约 2^64个值,而 set(集合)则是元素越多占用的内存就越多,两者形成了鲜明的对比
基数定义
基数定义:一个集合中不重复的元素个数就表示该集合的基数,比如集合 {1,2,3,1,2} ,它的基数集合为 {1,2,3} ,所以基数为 3。HyperLogLog 正是通过基数估计算法来统计输入元素的基数。
HyperLoglog 不会储存元素值本身,因此,它不能像 set 那样,可以返回具体的元素值。HyperLoglog 只记录元素的数量,并使用基数估计算法,快速地计算出集合的基数是多少。
场景应用
HyperLogLog 也有一些特定的使用场景,它最典型的应用场景就是统计网站用户月活量,或者网站页面的 UV(网站独立访客)数据等。
UV 与 PV(页面浏览量) 不同,UV 需要去重,同一个用户一天之内的多次访问只能计数一次。这就要求用户的每一次访问都要带上自身的用户 ID,无论是登陆用户还是未登陆用户都需要一个唯一 ID 来标识。
当一个网站拥有巨大的用户访问量时,我们可以使用 Redis 的 HyperLogLog 来统计网站的 UV (网站独立访客)数据,它提供的去重计数方案,虽说不精确,但 0.81% 的误差足以满足 UV 统计的需求。
常用命令
| 命令 | 说明 |
|---|---|
| PFADD key element [element ...] | 添加指定元素到 HyperLogLog key 中。 |
| PFCOUNT key [key ...] | 返回指定 HyperLogLog key 的基数估算值。 |
| PFMERGE destkey sourcekey [sourcekey ...] | 将多个 HyperLogLog key 合并为一个 key。 |
基本命令
HyperLogLog 提供了三个常用命令,分别是 PFADD、PFCOUNT和 PFMERGE。
下面看一组实例演示:假设有 6 个用户(user01-user06),他们分别在上午 8 与 9 点访问了www.baidu.com
#向指定的key中添加用户
127.0.0.1:6379> PFADD user:uv:2021011308 user01 user02 user03
(integer) 1
#向指定的key中添加用户
127.0.0.1:6379> PFADD user:uv:2021011309 user04 user05
(integer) 1
#统计基数值
127.0.0.1:6379> PFCOUNT user:uv:2021011308
(integer) 3
#重复元素不能添加成功,其基数仍然为3
127.0.0.1:6379> PFADD user:uv:2021011308 user01 user02
(integer) 0
127.0.0.1:6379> PFCOUNT user:uv:2021011308
(integer) 3
#添加新元素值
127.0.0.1:6379> PFADD user:uv:2021011308 user06
(integer) 1
#基数值变为4
127.0.0.1:6379> PFCOUNT user:uv:2021011308
(integer) 4
#统计两个key的基数值
127.0.0.1:6379> PFCOUNT user:uv:2021011308 user:uv:2021011309
(integer) 6
#将两个key值合并为一个
127.0.0.1:6379> PFMERGE user:uv:2021011308-09 user:uv:2021011308 user:uv:2021011309
OK
#使用合并后key统计基数值
127.0.0.1:6379> PFCOUNT user:uv:2021011308-09
(integer) 6
2.2.7 性能测试
2.2.7.1 测试命令格式
执行测试命令,要在 Redis 的安装目录下执行,命令如下所示:
redis-benchmark [option] [option value]
其中 option 为可选参数, option value 为具体的参数值。 redis-benchmark 命令的可选参数如下所示:
| 参数选项 | 说明 |
|---|---|
| -h | 指定服务器主机名。 |
| -p | 指定服务器端口。 |
| -s | 指定服务器 socket。 |
| -c | 指定并发连接数。 |
| -n | 指定请求的具体数量。 |
| -d | 以字节的形式指定 SET/GET 值的数据大小。 |
| -k | 1 表示 keep alive;0 表示 reconnect,默认为 1。 |
| -r | SET/GET/INCR 使用随机 key, SADD 使用随机值。 |
| -P | Pipeline 请求 |
| -q | 强制退出 Redis,仅显示 query/sec 值。 |
| --csv | 以 CSV 格式输出。 |
| -l | 生成循环,永久执行测试。 |
| -t | 仅运行以逗号分隔的测试命令列表。 |
| -I(大写i) | 空闲模式,打开 N 个空闲连接并等待连接。 |
在 Windows 系统下,其目录文件如图所示:
 图1:Redis Benchmark性能测试
图1:Redis Benchmark性能测试
2.2.7.2 执行测试命令
1) Windows环境
在 Windows 10 系统环境下,同时执行了 10000 个命令来检测 Redis 服务器的性能,示例如下:
E:\Redis-x64-5.0.14.1>redis-benchmark.exe -n 10000 -q
PING_INLINE: 153846.16 requests per second
PING_BULK: 172413.80 requests per second
SET: 185185.19 requests per second
GET: 149253.73 requests per second
INCR: 151515.16 requests per second
LPUSH: 70422.53 requests per second
RPUSH: 163934.42 requests per second
LPOP: 196078.44 requests per second
RPOP: 192307.69 requests per second
SADD: 140845.06 requests per second
HSET: 196078.44 requests per second
SPOP: 185185.19 requests per second
LPUSH (needed to benchmark LRANGE): 153846.16 requests per second
LRANGE_100 (first 100 elements): 25575.45 requests per second
LRANGE_300 (first 300 elements): 9775.17 requests per second
LRANGE_500 (first 450 elements): 6234.41 requests per second
LRANGE_600 (first 600 elements): 5125.58 requests per second
MSET (10 keys): 121951.22 requests per second
注意:若是 Linux 系统,其每秒钟执行的请求数量是 Windows 系统的好几倍。
2) Linux环境
Linux 环境下,Redis 的性能测试结果,如下所示:
[root@localhost src]# redis-benchmark -n 10000 -q
PING_INLINE: 149253.73 requests per second
PING_BULK: 178571.42 requests per second
SET: 196078.44 requests per second
GET: 192307.69 requests per second
INCR: 178571.42 requests per second
LPUSH: 158730.16 requests per second
RPUSH: 178571.42 requests per second
LPOP: 188679.25 requests per second
RPOP: 178571.42 requests per second
SADD: 200000.00 requests per second
HSET: 178571.42 requests per second
SPOP: 196078.44 requests per second
ZADD: 204081.64 requests per second
ZPOPMIN: 188679.25 requests per second
LPUSH (needed to benchmark LRANGE): 181818.19 requests per second
LRANGE_100 (first 100 elements): 90909.09 requests per second
LRANGE_300 (first 300 elements): 37878.79 requests per second
LRANGE_500 (first 450 elements): 28011.21 requests per second
LRANGE_600 (first 600 elements): 22471.91 requests per second
MSET (10 keys): 166666.67 requests per second
**3) 执行指定的测试命令 **
带参数的命令,使用示例如下:
#winddows平台
E:\Redis-x64-5.0.14.1>redis-benchmark.exe -h 127.0.0.1 -p 6379 -n 10000 -t set,get,lpush -q
SET: 166666.67 requests per second
GET: 172413.80 requests per second
LPUSH: 53191.49 requests per second
#Linux平台
[root@localhost src]# redis-benchmark -h 127.0.0.1 -p 6379 -n 10000 -t set,get,lpush -q
SET: 185185.19 requests per second
GET: 188679.25 requests per second
LPUSH: 181818.19 requests per second
2.2.8 CONFIG 动态修改配置
config 命令用于查看当前redis配置、以及不重启redis服务实现动态更改redis配置等
注意:config不是所有配置都可以动态修改,且此方式无法持久保存的,比如:客户端连接情况,redis服务端系统状态
config 查询redis服务配置项
#CONFIG GET 命令用于取得运行中的 Redis 服务器的配置参数(configuration parameters),在Redis 2.4 版本中, 有部分参数没有办法用 CONFIG GET 访问,但是在最新的 Redis 2.6 版本中,所有配置参数都已经可以用 CONFIG GET 访问了
config get connected_clients #redis客户端连接数
config get maxmemory #redis工作线程最大内存空间大小
#CONFIG GET命令支持模糊搜索配置项
127.0.0.1:6379> config get * #列表redis所有配置参数项
1) "dbfilename" #奇数行为key
2) "dump_6379.rdb" #偶数行为value
3) "requirepass"
4) ""
127.0.0.1:6379> CONFIG GET bind
1) "bind"
2) "0.0.0.0"
127.0.0.1:6379> CONFIG GET *pass*
1) "requirepass"
2) ""
config set 临时性状态修改redis配置项立即生效
config set <parameter> <value>
范例:config 设置连接密码
#config get requirepass 设置redis连接密码
127.0.0.1:6379> config set requirepass 123456
OK
#设置密码显示ok立即生效,此时不能查看redis信息,需要密码验证
127.0.0.1:6379> config get requirepass
(error) NOAUTH Authentication required.
#auth <password> 输入连接密码进行验证
127.0.0.1:6379> AUTH 123456
OK
#auth密码验证后再次查询配置项
127.0.0.1:6379> config get requirepass
1) "requirepass"
2) "123456"
范例:更改最大内存
127.0.0.1:6379> config get maxmemory
1) "maxmemory"
2) "0"
127.0.0.1:6379> config set maxmemory 209715200
OK
127.0.0.1:6379> config get maxmemory
1) "maxmemory"
2) "209715200"
2.2.9 服务器命令行中常用命令
下表介绍了 Redis 服务器的常用命令:
| 命令 | 说明 |
|---|---|
| BGREWRITEAOF | 在后台以异步的方式执行一个 AOF 文件的重写操作,对源文件进行压缩,使其体积变小。 AOF 是实现数据持久化存储的方式之一。 |
| BGSAVE | 在后台执行初始化操作,并以异步的方式将当前数据库的数据保存到磁盘中。 |
| CLIENT KILL [ip:port] [ID client-id] | 关闭客户端连接。 |
| CLIENT LIST | 获取连接到服务器的客户端连接列表。 |
| CLIENT GETNAME | 获取当前连接客户端的名称。 |
| CLIENT PAUSE timeout | 使服务器在指定的时间停止执行来自客户端的命令。 |
| CLIENT SETNAME connection-name | 设置当前连接客户端的名称。 |
| COMMAND | 返回所有 Redis 命令的详细描述信息。 |
| COMMAND COUNT | 此命令用于获取 Redis 命令的总数。 |
| COMMAND GETKEYS | 获取指定命令的所有键。 |
| INFO [section] | 获取 Redis 服务器的各种信息和统计数值。 |
| COMMAND INFO command-name [command-name ...] | 用于获取指定 Redis 命令的描述信息。 |
| CONFIG GET parameter | 获取指定配置参数的值。 |
| CONFIG REWRITE | 修改启动 Redis 服务器时所指定的 redis.conf 配置文件。 |
| CONFIG SET parameter value | 修改 Redis 配置参数,无需重启。 |
| CONFIG RESETSTAT | 重置 INFO 命令中的某些统计数据。 |
| DBSIZE | 返回当前数据库中 key 的数量。 |
| DEBUG OBJECT key | 获取 key 的调试信息。当 key 存在时,返回有关信息;当 key 不存在时,返回一个错误。 |
| DEBUG SEGFAULT | 使用此命令可以让服务器崩溃。 |
| FLUSHALL | 清空数据库中的所有键。 |
| FLUSHDB | 清空当前数据库的所有 key。 |
| LASTSAVE | 返回最近一次 Redis 成功将数据保存到磁盘上的时间,以 UNIX 格式表示。 |
| MONITOR | 实时打印出 Redis 服务器接收到的命令。 |
| ROLE | 查看主从实例所属的角色,角色包括三种,分别是 master、slave、sentinel。 |
| SAVE | 执行数据同步操作,将 Redis 数据库中的所有数据以 RDB 文件的形式保存到磁盘中。 RDB 是 Redis 中的一种数据持久化方式。 |
| SHUTDOWN [NOSAVE] [SAVE] | 将数据同步到磁盘后,然后关闭服务器。 |
| SLAVEOF host port | 此命令用于设置主从服务器,使当前服务器转变成为指定服务器的从属服务器, 或者将其提升为主服务器(执行 SLAVEOF NO ONE 命令)。 |
| SLOWLOG subcommand [argument] | 用来记录查询执行时间的日志系统。 |
| SYNC | 用于同步主从服务器。 |
| SWAPDB index index | 用于交换同一 Redis 服务器上的两个数据库,可以实现访问其中一个数据库的客户端连接,也可以立即访问另外一个数据库的数据。 |
| TIME | 此命令用于返回当前服务器时间。 |
三、Redis数据持久化
Redis所有数据都是保存在内存中。 Redis数据备份可以定期地通过异步方式保存到磁盘上,该方式称为半持久化模式,如果每一次数据变化都写人AOF文件里面,则称为全持久化模式。同时还可以基于 Redis主从复制实现 Redis备份与恢复
3.1 半持久化RDB模式(redis database)
3.1.1 自动触发持久化
半持久化RDB模式也是 Redis备份默认方式,是通过快照( snapshotting)完成的,当满足在 redis.conf配置文件中设置的条件时, Redis会自动将内存中的所有数据进行快照并存储在硬盘上,完成数据备份Redis进行RDB快照的条件由用户在配置文件中自定义,由两个参数构成:时间和改动的键的个数。当在指定的时间内被更改的键的个数大于指定的数值时就会进行快照。在配置文件中已经预置了以下3个条件
1)save 900 1:900s内有至少1个键被更改则进行快照。
2)save 300 10:300s内有至少10个键被更改则进行快照。
3)save 60 10000:60s内有至少10000个键被更改则进行快照
#关闭Redis服务自动快照备份
save ""
#yes时因空间满等原因快照无法保存出错时,禁止redis写入操作,建议为no
stop-writes-on-bgsave-error yes
#持久化到RDB文件时,是否压缩,"yes"为压缩,"no"则反之
rdbcompression yes
#是否对备份文件开启RC64校验,默认是开启
rdbchecksum yes
#快照文件名
dbfilename dump.rdb
#快照文件保存路径,示例:dir "/app/redis/data"
dir /app/redis/data
默认可以存在多个条件,条件之间是或的关系,只要满足其中一个条件,就会进行快照。
如果想禁用自动快照,只需要将所有的save参数删除即可。 Redis默认会将快照文件存储在 Redis数据目录,默认文件名为dump.rdb文件,可以通过配置dir和 filename两个参数分别指定快照文件的存储路径和文件名。也可以在 Redis命令行执行 config get dir获取
3.1.1.1 设置同步规则
打开redis.conf文件,加入如下配置
save 60 3 ##意思代表60s内有3个键发生变化,则自动持久化
3.1.1.2 设置key
[root@redis bin]# ./redis-cli -h 127.0.0.1
127.0.0.1:6379> set a 100
OK
127.0.0.1:6379> set b 200
OK
127.0.0.1:6379> set c 300
OK
127.0.0.1:6379> set d 400
OK
127.0.0.1:6379> exit
[root@redis bin]# ll
total 18464
-rw-r--r-- 1 root root 121 Oct 29 20:24 dump.rdb ##发现数据已经被持久化
3.1.1.3 测试数据是否被持久化
将redis停止,同时将dump.rdb文件改名,查看数据是否存在
##停止redis
[root@redis bin]# ps -ef |grep redis
root 27578 1 0 20:25 ? 00:00:00 ./redis-server 127.0.0.1:6379
root 27684 23908 0 20:27 pts/1 00:00:00 grep --color=auto redis
[root@redis bin]# kill -9 27578
##将rdb文件别名
[root@redis bin]# mv dump.rdb dump.rdb.bak
##启动redis查看数据是否存在
[root@redis bin]# ./redis-server /usr/local/src/redis-6.0.16/redis.conf
[root@redis bin]# ./redis-cli -h 127.0.0.1
127.0.0.1:6379> keys *
(empty array) ##是空的,说明数据没有被持久化
##将redis数据库停止
[root@redis bin]# ps -ef |grep redis
root 28360 1 0 20:40 ? 00:00:00 ./redis-server 127.0.0.1:6379
root 28384 23847 0 20:40 pts/0 00:00:00 grep --color=auto redis
[root@redis bin]# kill -9 28360
##将rdb文件重新修改成dump.rdb,并重启redis
[root@redis bin]# mv dump.rdb.bak dump.rdb
[root@redis bin]# ./redis-server /usr/local/src/redis-6.0.16/redis.conf
[root@redis bin]# ./redis-cli -h 127.0.0.1
127.0.0.1:6379> keys * ##数据恢复了
1) "b"
2) "d"
3) "a"
4) "c"
3.1.2 手动操作持久化
##save持久化---阻塞型
[root@redis bin]# ./redis-cli -h 127.0.0.1
127.0.0.1:6379> keys *
(empty array)
127.0.0.1:6379> set name zhangsan
OK
127.0.0.1:6379> set age 30
OK
127.0.0.1:6379> set add hubei
OK
127.0.0.1:6379> save ##手动持久化
OK
##查看数据
[root@redis src]# vim dump.rdb
[root@redis src]# cat dump.rdb
REDIS0009 redis-ver6.0.16
redis-bitse^
]used-memP%
aof-preamble~mzhangsanaddhubeiageÿÿ皪 ##数据是不可读的,只能看到大概数据
#bgsave手动同步 ----非阻塞型
[root@redis bin]# ./redis-cli -h 127.0.0.1
127.0.0.1:6379> set a 100
OK
127.0.0.1:6379> set b 200
OK
127.0.0.1:6379> bgsave
Background saving started
127.0.0.1:6379>
注意:
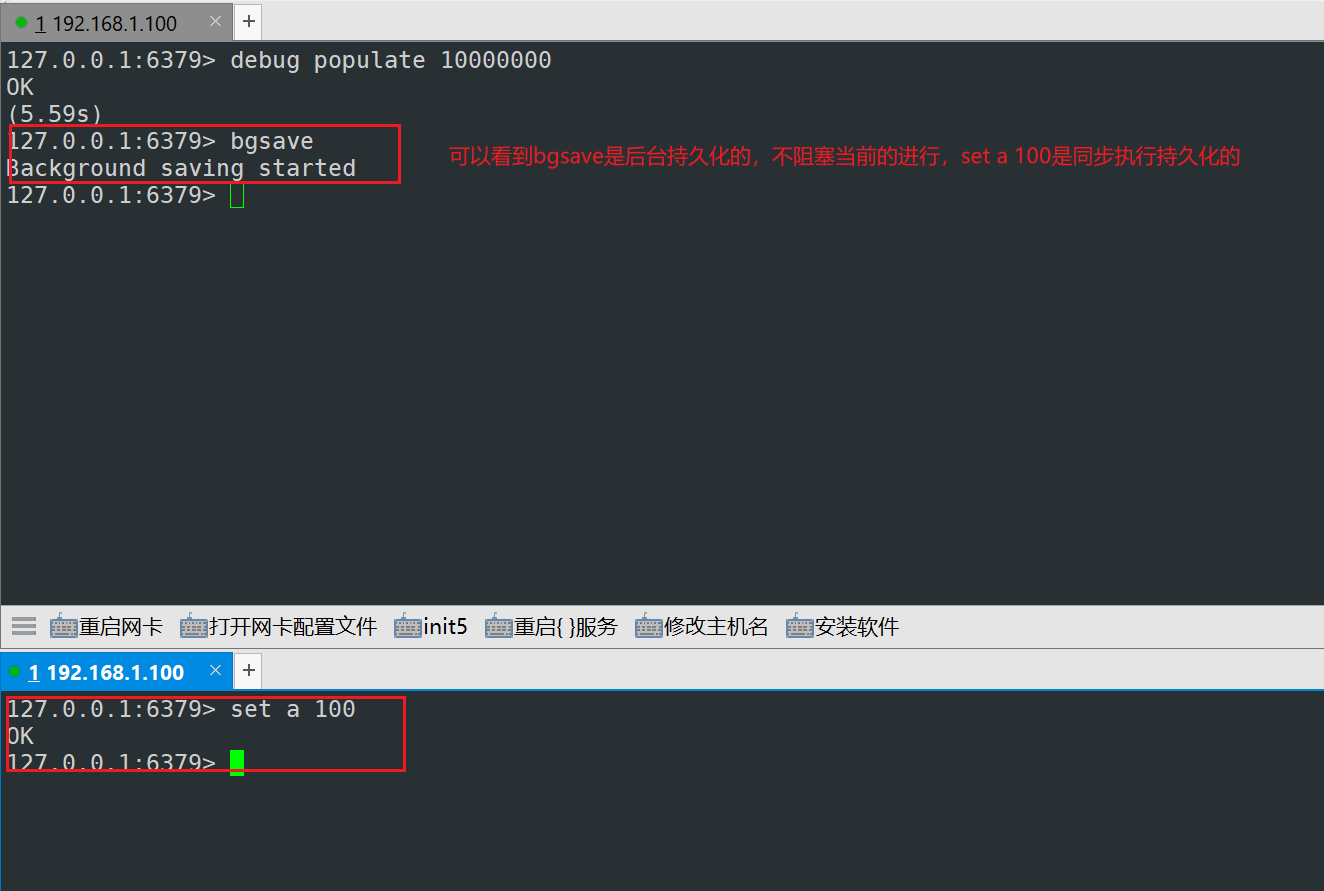
save:该命令会阻塞redis服务器,执行save期间,redis不能再处理其他命令,直到RDB过程完成为止,优点是操作简单
bgsave:该命令不会阻塞redis,会生成一个分支线程来进行持久化,主线程仍然能够接收命令操作,优点是对用户友好。
3.1.2.1 模拟save和bgsave数据持久化过程
为了演示,我们一次性在redis数据库中增加1000W条数据
1)save持久化
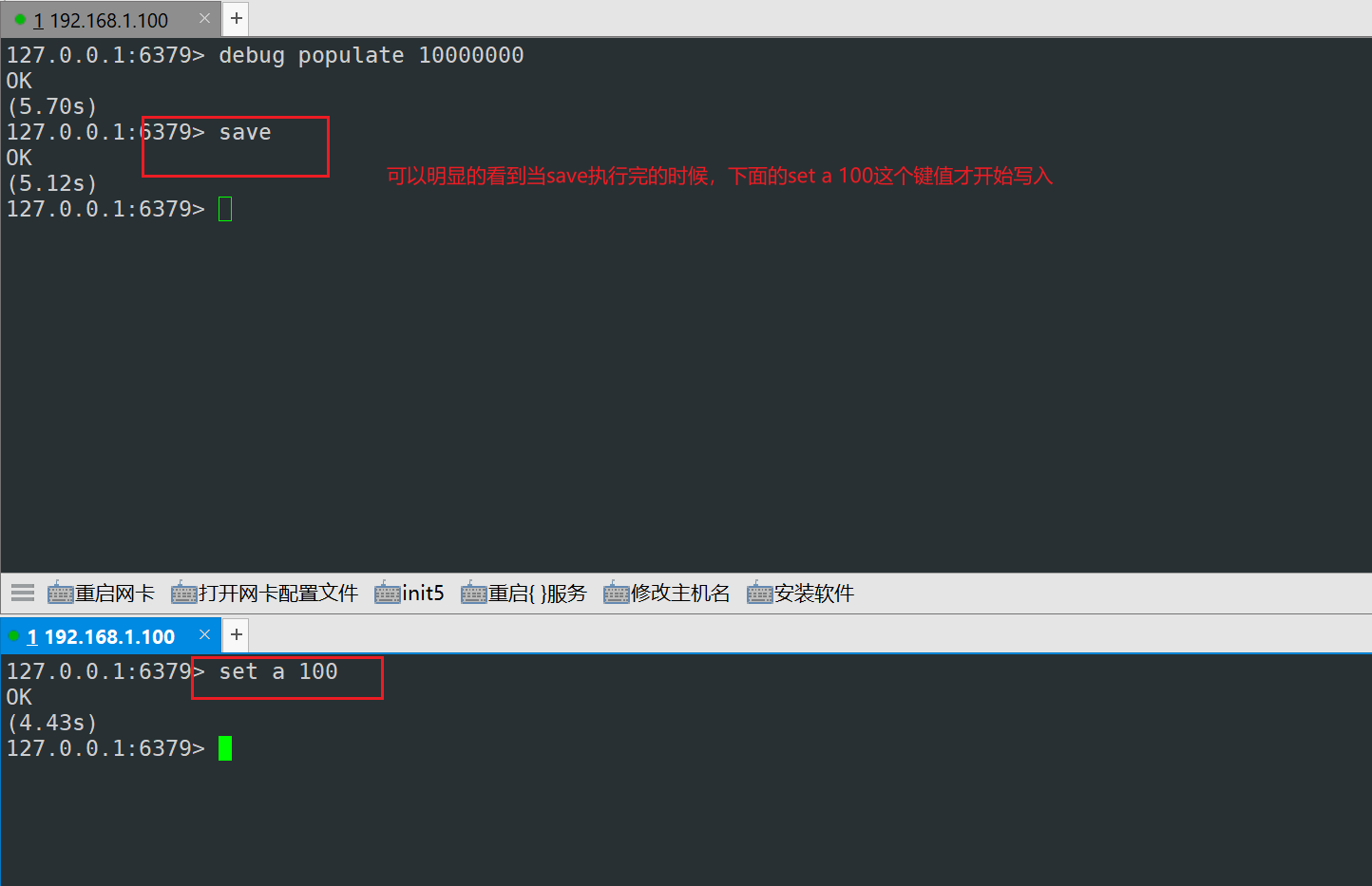
2)bgsave持久化
3.1.2.2 同步后的备份数据
[root@redis bin]# ll
total 279964
-rw-r--r-- 1 root root 267777882 Oct 29 19:45 dump.rdb ##大小急剧增加
3.1.2.3 Redis bgsave实现数据持久化过程
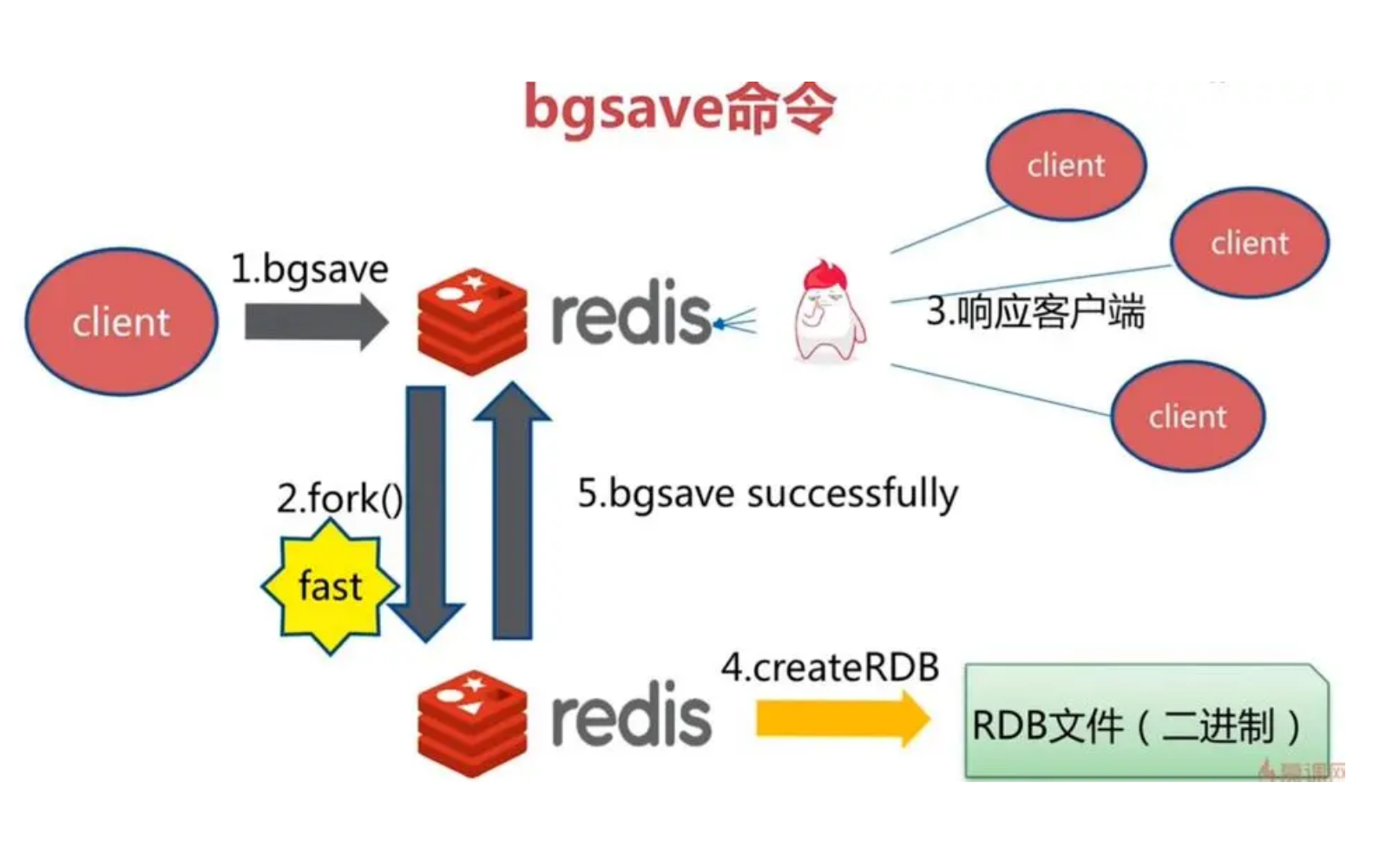
1、Redis父进程首先判断:当前是否在执行save,或bgsave/bgrewriteaof的子进程,如果在执行则bgsave命令直接返回。bgsave/bgrewriteaof(aof) 的子进程不能同时执行,主要是基于性能方面的考虑:两个并发的子进程同时执行大量的磁盘写操作,可能引起严重的性能问题。
2、父进程执行fork操作创建子进程,这个过程中父进程是阻塞的,Redis不能执行来自客户端的任何命令
3、父进程fork后,bgsave命令返回”Background saving started”信息并不再阻塞父进程,并可以响应其他命令
4、子进程创建RDB文件,根据父进程内存快照生成临时快照文件,完成后对原有文件进行原子替换
5、子进程发送信号给父进程表示完成,父进程更新统计信息
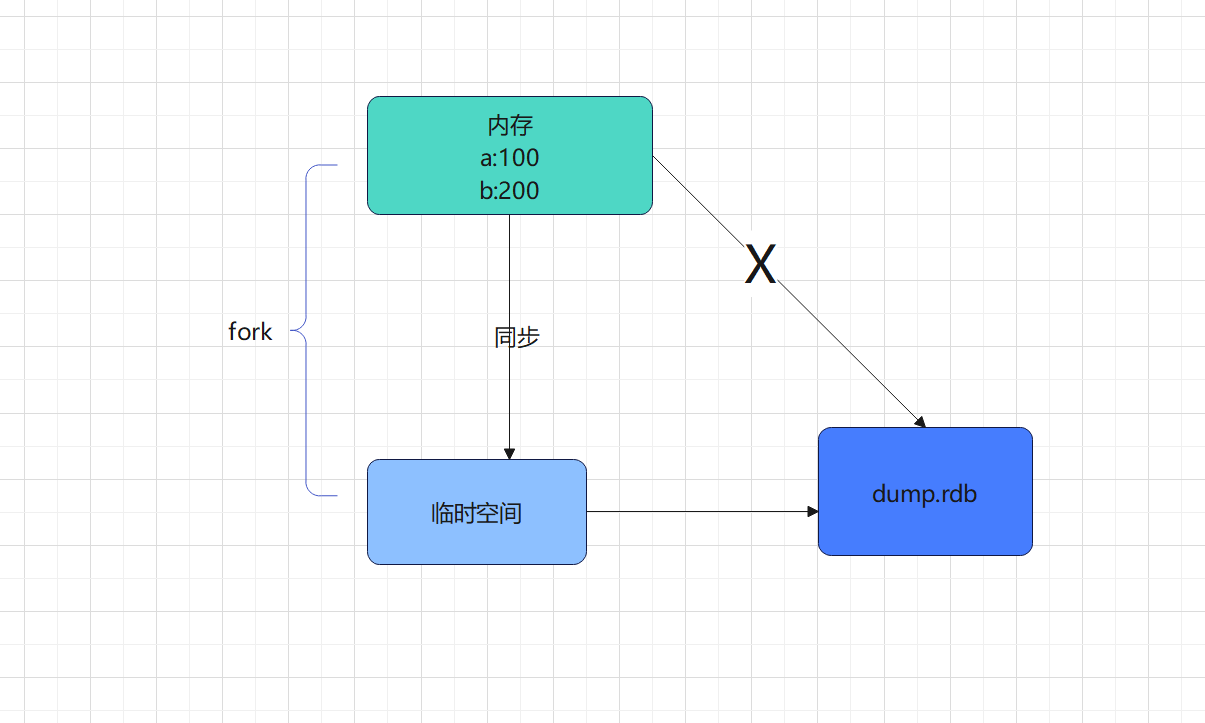
3.1.3 RDB的备份过程
Redis从master主进程先fork出一个子进程,使用写时复制机制,子进程将内存的数据保存为一个临时文件,比如`temp-<子进程pid>.rdb`,当数据保存完成之后再将上一次保存的RDB文件替换掉,然后关闭子进程,这样可以保存每一次做RDB快照的时候保存的数据都是完整的,因为直接替换RDB文件的时候可能会出现突然断电等问题而导致RDB文件还没有保存完整就突然关机停止保存而导致数据丢失的情况,可以手动将每次生成的RDB文件进程备份,这样可以最大化保存历史数据。
3.1.4 fork概念
Fork 的作用是复制一个与当前进程一样的进程。新进程的所有数据( 变量、环境变量、程序计数器等) 数值都和原进程一致,但是是一个全新的进程,并作为原进程的子进程
在Linux 程序中,fork()会产生一个和父进程完全相同的子进程,但子进程在此后多会exec 系统调用,出于效率考虑,Linux才引入了 “写时复制技术“
一般情况父进程和子进程会共用同一段物理内存,只有进程空间的各段的内容要发生变化时,才会将父进程的内容复制一份给子进程。
3.1.5 RDB的优缺点
3.1.5.1 优点
1、适合大规模的恢复
2、对数据完整和一致性要求不高的场景
3、节省磁盘空间
4、恢复速度快
3.1.5.2 缺点
1、fork的时候需要复制一份内存中的数据,需要大致2倍内存空间的大小的空间存储临时文件--原有的dump.rdb
2、周期性备份数据,如果redis意外宕掉的话容易出现最后一次快照后的数据
3、fork的时候使用了“写时复制”技术,但是数据量过大的话,也会消耗服务器的性能
3.1.6 一键脚本备份RDB文件
#!/bin/bash
. /etc/init.d/functions
#rdb文件备份目录
BACKUP=/backup/redis-rdb
#rdb文件目录
DIR=/app/redis/data
#rdb文件basename
FILE=dump_6379
#连接redis信息
HOST=127.0.0.1
PASS=123456
PORT=6379
#执行bgsave,备份Redis快照数据
rediscli=/app/redis/bin/redis-cli
$rediscli -h $HOST -a $PASS -p $PORT --no-auth-warning bgsave
result=`$rediscli -h $HOST -a $PASS -p $PORT --no-auth-warning info Persistence |grep rdb_bgsave_in_progress| sed -rn 's/.*:([0-9]+).*/\1/p'`
while [[ ! $result -eq 0 ]] ; do
sleep 1
result=`$rediscli -h $HOST -a $PASS -p $PORT --no-auth-warning info Persistence |grep rdb_bgsave_in_progress| sed -rn 's/.*:([0-9]+).*/\1/p'`
done
DATE=`date +%F_%H-%M-%S`
[ -e $BACKUP ] || { mkdir -p $BACKUP; chown -R redis.redis $BACKUP; }
mv ${DIR}/${FILE}.rdb ${BACKUP}/${FILE}-${DATE}.rdb
action "BACKUP REDIS RDB"
3.2 全持久化AOF模式(append only file)
如果数据很重要无法承受任何损失,可以考虑使用AOF方式进行持久化,默认 Redis没有开启AOF方式的全持久化模式。在启动时 Redis会逐个执行AOF文件中的命令来将硬盘中的数据载入到内存中,备份以日志的形式来记录每个写操作(增量保存),将Redis 执行过的所有写指令记录下来(读操作不记录),只许追加文件但不可以改写文件,redis 启动之初会读取该文件重新构建数据,换言之,redis 重启的话就根据日志文件的内容特写指令从前到后执行,以完成数据的恢复工作。
Redis允许同时开启AOF和RDB,既保证了数据安全又使得进行备份等操作十分容易此时重新启动 Redis后Reds会使用AOF文件来恢复数据,因为AOF方式的持久化可能丢失的数据更少,可以在 redis.conf中通过 appendonly参数开启 Redis AOF全持久化
3.2.1 编辑redis的配置文件
#dir目录是存放Redis持久化数据文件目录
dir /app/redis/data
#appendnoly设置为yes开启AOF模式,默认redis使用的是rdb方式持久化,这种方式在许多应用中已经足够用了,但是redis如果中途宕机,会导致可能有几分钟的数据丢失(取决于dumpd数据的间隔时间),根据save来策略进行持久化,Append Only File是另一种持久化方式,可以提供更好的持久化特性,Redis会把每次写入的数据在接收后都写入 appendonly.aof 文件,每次启动时Redis都会先把这个文件的数据读入内存里,先忽略RDB文件。默认不启用此功能
appendonly no
#AOF文件名,是文本文件,存放在dir指令指定的目录中
appendfilename "appendonly.aof"
#aof持久化策略的配置
#no表示redis不自动执行fsync,由操作系统保证数据同步到磁盘,Linux的默认fsync策略是30秒,最多会丢失30s的数据
#always表示每次写入都执行fsync,以保证数据同步到磁盘,但是会生成大量磁盘IO
#everysec表示每秒执行一次fsync,可能会导致丢失这1s数据
appendfsync everysec
#在aof rewrite期间,是否对aof新记录的append暂缓使用文件同步策略,主要考虑磁盘IO开支和请求阻塞时间
no-appendfsync-on-rewrite no
#同时在执行bgrewriteaof操作和主进程写aof文件的操作,两者都会操作磁盘,而bgrewriteaof往往会涉及大量磁盘操作,这样就会造成主进程在写aof文件的时候出现阻塞的情形,以下参数实现控制
#默认为no,表示"不暂缓",新的aof记录仍然会被立即同步到磁盘,是最安全的方式,不会丢失数据,但是要忍受阻塞的问题
#为yes,相当于将appendfsync设置为no,这说明并没有执行磁盘操作,只是写入了缓冲区,因此这样并不会造成阻塞(因为没有竞争磁盘),但是如果这个时候redis挂掉,就会丢失数据。丢失多少数据呢?Linux的默认fsync策略是30秒,最多会丢失30s的数据,但由于yes性能较好而且会避免出现阻塞因此比较推荐
#从 Redis 2.4 开始, AOF 重写由 Redis 自行触发, BGREWRITEAOF 仅仅用于手动触发重写操作
#当Aof log增长超过上次rewrite整理数据文件大小指定百分比例时,重写AOF文件,设置为0表示不自动重写Aof日志,重写是为了使aof体积保持最小,但是还可以确保保存最完整的数据
auto-aof-rewrite-percentage 100
#自动触发aof rewrite的最小文件大小
#当AOF文件大小达到64M,自动触发rewrite重写整理;当AOF文件大小超过了64M时,按照 auto-aof-rewrite-percentage 增长百分比触发rewrite
auto-aof-rewrite-min-size 64mb
#是否加载由于某些原因导致的末尾异常的AOF文件(主进程被kill/断电等),建议yes
aof-load-truncated yes
aof-use-rdb-preamble no
#redis4.0新增RDB-AOF混合持久化格式,在开启了这个功能之后,AOF重写产生的文件将同时包含RDB格式的内容和AOF格式的内容,其中RDB格式的内容用于记录已有的数据,而AOF格式的内容则用于记录最近发生了变化的数据,这样Redis就可以同时兼有RDB持久化和AOF持久化的优点(既能够快速地生成重写文件,也能够在出现问题时,快速地载入数据),默认为no,即不启用此功能
注意:当Redis数据库中存有一定量数据时后,不建议直接修改Redis配置文件开启AOF模式功能;原因是AOF文件比RDB文件优先级高在启动Redis服务,首先忽略RDB文件,直接加载AOF文件数据,但是开启AOF模式功能之前数据并没有记录到AOF文件,此时AOF文件不存在相当于空,一旦启动Redis服务,Redis数据库中数据会被清空
正确开启AOF模式功能
- 第一步:Redis服务运行,通过config 动态开启AOF功能,把现有数据记录到AOF文件中
- 第二步:修改Redis配置文件,从而保证持久开启AOF功能
#config动态临时开启aof功能
[root@centos7 ~ ]# redis-cli -h 127.0.0.1 -a 123456 --no-auth-warning config set appendonly yes
OK
[root@centos7 ~ ]# redis-cli -h 127.0.0.1 -a 123456 --no-auth-warning config get appendonly
1) "appendonly"
2) "yes"
#AOF模式开启子进程
[root@centos7 ~ ]# pstree -p
├─redis-server(2591)─┬─redis-server(2751)
│ ├─{redis-server}(2592)
│ ├─{redis-server}(2593)
│ └─{redis-server}(2594)
#AOF生成数据文件时也会生成临时文件
[root@centos7 ~ ]# ll /app/redis/data/
-rw-r--r-- 1 redis redis 0 Sep 13 22:59 appendonly.aof
-rw-r--r-- 1 redis redis 120620934 Sep 13 20:24 dump_6379.rdb
-rw-r--r-- 1 redis redis 50868229 Sep 13 23:06 temp-rewriteaof-2751.aof
#Redis会在配置项dir指定目录下生成appendonly.aof文件,记录当前Redis存放的数据信息
[root@centos7 ~ ]# ll /app/redis/data/
-rw-r--r-- 1 redis redis 120620934 Sep 13 22:59 appendonly.aof
-rw-r--r-- 1 redis redis 120620934 Sep 13 20:24 dump_6379.rdb
#查看日志
[root@centos7 ~ ]# tail -f /app/redis/log/redis_6379.log
2591:M 13 Sep 2021 23:11:42.722 * Background append only file rewriting started by pid 2823
2591:M 13 Sep 2021 23:11:46.982 * AOF rewrite child asks to stop sending diffs.
2823:C 13 Sep 2021 23:11:46.982 * Parent agreed to stop sending diffs. Finalizing AOF...
2823:C 13 Sep 2021 23:11:46.982 * Concatenating 0.00 MB of AOF diff received from parent.
2823:C 13 Sep 2021 23:11:46.982 * SYNC append only file rewrite performed
2823:C 13 Sep 2021 23:11:46.988 * AOF rewrite: 6 MB of memory used by copy-on-write
2591:M 13 Sep 2021 23:11:47.001 * Background AOF rewrite terminated with success
2591:M 13 Sep 2021 23:11:47.001 * Residual parent diff successfully flushed to the rewritten AOF (0.00 MB)
2591:M 13 Sep 2021 23:11:47.001 * Background AOF rewrite finished successfully
#修改Redis配置文件
[root@centos7 ~ ]# vim /app/redis/etc/redis_6379.conf
appendonly yes
3.2.2 如果rdb和aof同时存在,听谁的?
127.0.0.1:6379> keys * ##查看数据库是空
(empty array)
127.0.0.1:6379> exit
[root@redis bin]# ll
total 18540
-rw-r--r-- 1 root root 79583 Oct 29 20:53 dump.rdb ##rdb存在数据
-rwxr-xr-x 1 root root 738264 Oct 29 13:46 redis-benchmark
-rwxr-xr-x 1 root root 5697416 Oct 29 13:46 redis-check-aof
-rwxr-xr-x 1 root root 5697416 Oct 29 13:46 redis-check-rdb
-rwxr-xr-x 1 root root 1065840 Oct 29 13:46 redis-cli
lrwxrwxrwx 1 root root 12 Oct 29 13:46 redis-sentinel -> redis-server
-rwxr-xr-x 1 root root 5697416 Oct 29 13:46 redis-server
[root@redis bin]# cd ..
[root@redis redis]# ll
total 84
-rw-r--r-- 1 root root 0 Oct 29 21:31 appendonly.aof ##aof是空的
drwxr-xr-x 2 root root 150 Oct 29 21:28 bin
-rw-r--r-- 1 root root 85573 Oct 29 21:30 redis.conf
当RDB和AOF同时存在时,系统默认优先读取AOF的数据。
3.2.3 AOF的备份恢复
3.2.3.1 在redis中添加4个键值
[root@redis bin]# ./redis-cli -h 127.0.0.1
127.0.0.1:6379> set aa 11
OK
127.0.0.1:6379> set bb 22
OK
127.0.0.1:6379> set cc 33
OK
127.0.0.1:6379> set dd 44
OK
127.0.0.1:6379>exit
[root@redis redis]# ll
total 92
-rw-r--r-- 1 root root 197 Oct 29 21:39 appendonly.aof ##查看数据已经被持久化
drwxr-xr-x 2 root root 150 Oct 29 21:28 bin
-rw-r--r-- 1 root root 122 Oct 29 21:40 dump.rdb
-rw-r--r-- 1 root root 85573 Oct 29 21:39 redis.conf
[root@redis redis]#
3.2.3.2 AOF的备份恢复
##查看redis的Pid,并将redis关闭
[root@redis bin]# ps -ef |grep redis
root 31634 1 0 21:44 ? 00:00:00 /usr/local/redis/bin/redis-server 127.0.0.1:6379
root 31688 30723 0 21:45 pts/0 00:00:00 grep --color=auto redis
[root@redis bin]# kill -9 31634
##将aof文件改名
[root@redis bin]# mv appendonly.aof appendonly.aof.bak
##重新启动redis,查看数据是否存在
[root@redis bin]# /usr/local/redis/bin/redis-server /usr/local/redis/redis.conf
[root@redis bin]# ./redis-cli -h 127.0.0.1
127.0.0.1:6379> keys * ##发现已经为空
(empty array)
127.0.0.1:6379> exit
##重新恢复aof文件
[root@redis bin]# mv appendonly.aof.bak appendonly.aof
mv: overwrite ‘appendonly.aof’? y ##覆盖
[root@redis bin]# ll
total 18468
-rw-r--r-- 1 root root 139 Oct 29 21:45 appendonly.aof
-rw-r--r-- 1 root root 122 Oct 29 21:45 dump.rdb
-rwxr-xr-x 1 root root 738264 Oct 29 13:46 redis-benchmark
-rwxr-xr-x 1 root root 5697416 Oct 29 13:46 redis-check-aof
-rwxr-xr-x 1 root root 5697416 Oct 29 13:46 redis-check-rdb
-rwxr-xr-x 1 root root 1065840 Oct 29 13:46 redis-cli
lrwxrwxrwx 1 root root 12 Oct 29 13:46 redis-sentinel -> redis-server
-rwxr-xr-x 1 root root 5697416 Oct 29 13:46 redis-server
##重新启动redis
[root@redis bin]# ps -ef |grep redis
root 31727 1 0 21:46 ? 00:00:00 /usr/local/redis/bin/redis-server 127.0.0.1:6379
[root@redis bin]# kill 31727
[root@redis bin]# /usr/local/redis/bin/redis-server /usr/local/redis/redis.conf
##查看数据,已经恢复
[root@redis bin]# ./redis-cli -h 127.0.0.1
127.0.0.1:6379> keys *
1) "cc"
2) "dd"
3) "aa"
4) "bb"
3.2.4 AOF的修复
AOF文件一旦遇到损坏,我们可以利用redis自带的redis-check-aof这个功能进行恢复
3.2.4.1 模拟破坏appendonly.aof文件
vim appendonly.aof打开文件
set
$2
cc
$2
33
*3
$3
set
$2
dd
$2
44
hello ##添加这一行数据,模拟损坏的场景
3.2.4.2 重新启动redis
[root@redis bin]# /usr/local/redis/bin/redis-server /usr/local/redis/redis.conf
[root@redis bin]# ./redis-cli -h 127.0.0.1
Could not connect to Redis at 127.0.0.1:6379: Connection refused ##连接失败
not connected>
3.2.4.3 修复
[root@redis bin]# ./redis-check-aof --fix appendonly.aof
0x 8b: Expected prefix '*', got: 'h' ##提示有异常
AOF analyzed: size=146, ok_up_to=139, diff=7
This will shrink the AOF from 146 bytes, with 7 bytes, to 139 bytes
Continue? [y/N]: y ##按Y
Successfully truncated AOF ##提示修复成功
3.2.4.4 再次启动redis
[root@redis bin]# /usr/local/redis/bin/redis-server /usr/local/redis/redis.conf
[root@redis bin]# ./redis-cli -h 127.0.0.1
127.0.0.1:6379> keys * ##看到数据又恢复了。
1) "aa"
2) "cc"
3) "dd"
4) "bb"
127.0.0.1:6379>
3.2.5 AOF的fsync的策略
1)always:每次写入一条数据,就立即将这个数据对应的写日志fsync到磁盘上去,性能非常的差,吞吐量非常低,如果非要保证redis不能丢失数据,那就只能这样子了。
2)everysec:每秒将os cache中的数据fsync到磁盘,这个最常用,并且redis默认也是这个策略,生产环境一般也是这么配置,性能也很高,QPS可达到上万。
3)no:仅仅将数据刷入到os cache中就不管了,然后就只能靠os cache自己的刷盘策略,时不时的将os cache中的数据刷入磁盘
3.2.6 rewrite 的策略
AOF是以不断向文件追加操作记录,当定义 x=100,修改为 x=200,业务调整又把x删除 del x,但这些操作记录都会记录在AOF文件,造成AOF文件记录信息庞大且无用记录太大
AOF rewrite功能:将一些重复的,无用的,过时的数据进行整理合并的,过期的数据重新写入一个新的AOF文件,从而节约AOF备份占用的硬盘空间,也能加速恢复过程;可以手动执行bgrewriteaof 触发AOF,或定义自动rewrite策略
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
该策略配置的意思是:如果上一次rewrite之后AOF文件是128M,然后就会接着128M继续写,如果发现增长的比例,超过之前大小的100%,也就是256M,那么就会触发一次rewrite,但是在触发之前还有和min-size的64mb比较一下大小,如果大于这个最小值,才触发。
3.2.6.1 rewrite的工作流程
1)redis fork一个子进程。
2)子进程基于当前内存中的数据,构建日志,开始往一个新的临时的AOF文件中写入日志。
3)redis主进程,接收到client新的写操作指令后,在内存中写入日志,同时新的日志指令也会在旧的AOF日志文件中写入。
4)子进程写完新的日志文件之后,redis主进程将内存中新写入的日志指令信息追加到这个新的AOF文件中。
5)用新的AOF文件替换旧的文件。
3.2.7 AOF的持久化过程
1)客户端的请求写命令会被 append 追加到 AOF 缓冲区内
2)AOF缓冲区根据 AOF持久化策路[always,everysec,no]将操作 sync 同步到磁盘的AOF 文件中
3)AOF 文件大小超过重写策略或手动重写时,会对 AOF 文件rewrite 重写,压缩AOF 文件容量
4)Redis 服务重启时,会重新 load 加载AOF 文件中的写操作达到数据恢复的目的
3.2.8 AOF的优缺点
3.2.8.1 AOF的优点
1)数据备份机制更高,数据安全性好
2)文本可读,可以操作AOF文件进行数据修复
3.2.8.2 AOF的缺点
1)比RDB占用更多的磁盘空间
2)恢复备份的速度比RDB慢
3)每次都做读写同步的话,性能压力比较大
3.2.9 AOF和RDB对比

3.3 Redis 淘汰策略
思考:Redis的数据已经设置了TTL,不是过期就已经删除了吗?为什么还存在所谓的淘汰策略呢?这个原因我们需要从redis的过期策略聊起。
3.3.1 过期策略
3.3.1.1 定期删除
redis 会将每个设置了过期时间的 key 放入到一个独立的字典中,以后会定期遍历这个字典来删除到期的 key。
Redis 默认会每秒进行十次过期扫描(100ms一次),过期扫描不会遍历过期字典中所有的 key,而是采用了一种简单的贪心策略。
例如:
1) 从过期字典中随机 20 个 key;
2) 删除这 20 个 key 中已经过期的 key;
3) 如果过期的 key 比率超过 1/4,那就重复步骤 1;
redis默认是每隔 100ms就随机抽取一些设置了过期时间的key,检查其是否过期,如果过期就删除。注意这里是随机抽取的。为什么要随机呢?你想一想假如 redis 存了几十万个 key ,每隔100ms就遍历所有的设置过期时间的 key 的话,就会给 CPU 带来很大的负载。
3.3.1.2 惰性删除
所谓惰性策略就是在客户端访问这个key的时候,redis对key的过期时间进行检查,如果过期了就立即删除,不会给你返回任何东西。
定期删除可能会导致很多过期key到了时间并没有被删除掉。所以就有了惰性删除。假如你的过期 key,靠定期删除没有被删除掉,还停留在内存里,除非你的系统去查一下那个 key,才会被redis给删除掉。这就是所谓的惰性删除,即当你主动去查过期的key时,如果发现key过期了,就立即进行删除,不返回任何东西.
总结:定期删除是集中处理,惰性删除是零散处理。
3.3.2 为什么需要淘汰策略
有了以上过期策略的说明后,就很容易理解为什么需要淘汰策略了,因为不管是定期采样删除还是惰性删除都不是一种完全精准的删除,就还是会存在key没有被删除掉的场景,所以就需要内存淘汰策略进行补充。
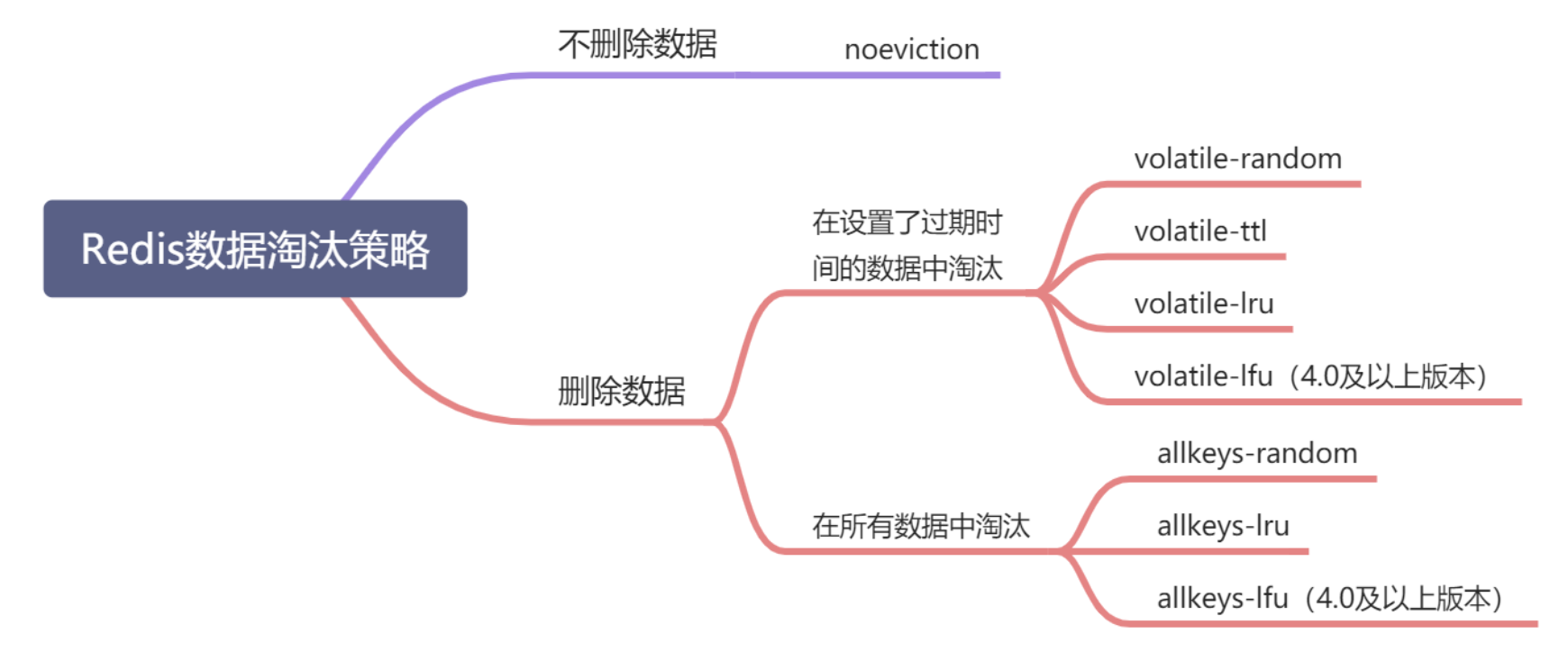
在使用Redis的过程中,当Redis缓存被写满之后,Redis就会根据配置的淘汰策略进行数据淘汰。从Redis4.0之后一共有8种淘汰策略。我们来分别看一下。
3.3.3 内存淘汰策略
3.3.3.1 noeviction
不进行数据淘汰,也是Redis的默认配置。这时,当缓存被写满时,再有写请求进来,Redis不再提供服务,直接返回错误。
3.3.3.2 volatile-random
缓存满了之后,在设置了过期时间的键值对中进行随机删除。
3.3.3.3 volatile-ttl
缓存满了之后,会针对设置了过期时间的键值对中,根据过期时间的先后顺序进行删除,越早过期的越先被删除。
3.3.3.4 volatile-lru
缓存满了之后,针对设置了过期时间的键值对,采用LRU算法进行淘汰
3.3.3.5 volatile-lfu
缓存满了之后,针对设置了过期时间的键值对,采用LFU的算法进行淘汰。
3.3.3.6 allkeys-random
缓存满了之后,从所有键值对中随机选择并删除数据。
3.3.3.7 allkeys-lru
缓存写满之后,使用LRU算法在所有的数据中进行筛选删除。
3.3.3.8 allkeys-lfu
缓存满了之后,使用LRU算法在所有的数据中进行筛选删除。
一张图总结:
在日常使用过程中,主要根据你的数据要求来配置相应的策略,这里我给你三点建议。
1)我们优先使用allkeys-lru 策略。这样,我们就可以借助LRU算法去淘汰那些不常用的数据,把最近最常用的放在缓存中,从而提高应用的性能。如果你的数据有明显的冷热区分,建议你使用allkeys-lru策略。
2) 如果你的数据的访问频率相差不大,也没有冷热之分,直接使用allkeys-random 策略,随机选择淘汰的数据就行。
3) 如果你的数据有置顶要求,比如置顶新闻等。那么我们就选择volatile-lru策略,同时不给置顶数据设置过期时间,这样一来,置顶的数据永远不会被删除,而其他设置了过期时间的数据,会更加LRU算法进行淘汰。
3.3.4 关于LRU和LFU算法
LRU(Least Recently Used),即最近最少使用,是一种缓存置换算法。在使用内存作为缓存的时候,缓存的大小一般是固定的。当缓存被占满,这个时候继续往缓存里面添加数据,就需要淘汰一部分老的数据,释放内存空间用来存储新的数据。这个时候就可以使用LRU算法了。其核心思想是:如果一个数据在最近一段时间没有被用到,那么将来被使用到的可能性也很小,所以就可以被淘汰掉。
其原理是维护一个双向链表,key -> node,其中node保存链表前后节点关系及数据data。新插入的key时,放在头部,并检查是否超出总容量,如果超出则删除最后的key;访问key时,无论是查找还是更新,将该Key被调整到头部。
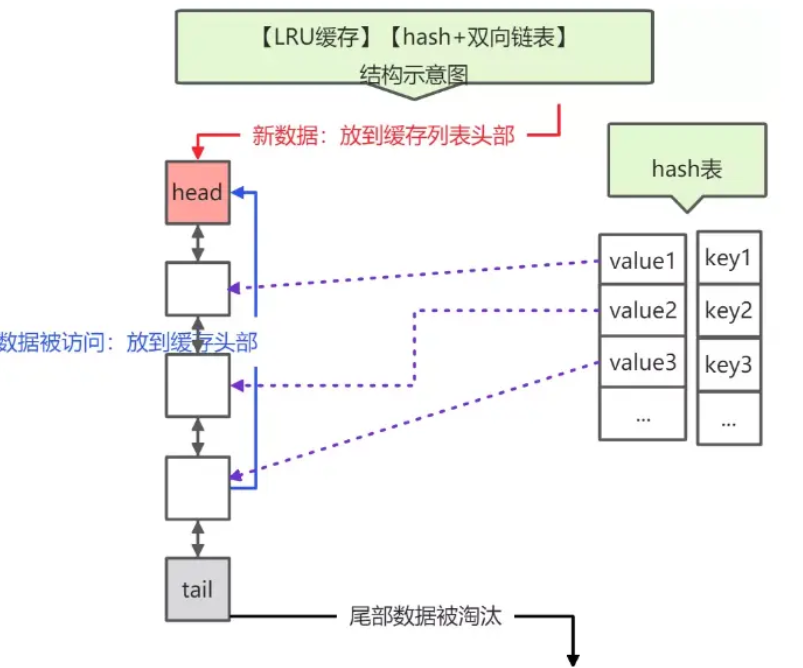
当 Redis 进行内存淘汰时,会使用随机采样的方式来淘汰数据,它是随机取 5 个值(此值可配置),然后淘汰最久没有使用的那个。
# maxmemory <bytes> #定义redis使用的最大内存
# maxmemory-policy noeviction #定义redis内存淘汰策略
# maxmemory-samples 5 #淘汰采样的值
注意:
Redis的LRU算法不是一个严格的LRU实现,这意味着Redis不能选择最久未被访问的那些键。Redis会尝试执行一个近似LRU的算法,通过采样一小部分键,然后再采样键中回收最适合的那个。
从Redis3.0开始,算法被改进为维护一个回收候选键池。这改善了算法的性能,使得更接近于真实的LRU算法的行为。Redis的LRU算法有一点很重要,你可以调整算法的精度,通过改变每次回收时检查的采样数量。
maxmemory-samples 5
Redis 实现的 LRU 算法的优点:
- 不用为所有的数据维护一个大链表,节省了空间占用;
- 不用在每次数据访问时都移动链表项,提升了缓存的性能;
但是 LRU 算法有一个问题,无法解决缓存污染问题,比如应用一次读取了大量的数据,而这些数据只会被读取这一次,那么这些数据会留存在 Redis 缓存中很长一段时间,造成缓存污染。
因此,在 Redis 4.0 之后引入了 LFU 算法来解决这个问题。
LFU 全称是 Least Frequently Used 翻译为最近最不常用的,LFU 算法是根据数据访问次数来淘汰数据的,它的核心思想是“如果数据过去被访问多次,那么将来被访问的频率也更高”。
LFU算法能更好的表示一个key被访问的热度。假如你使用的是LRU算法,一个key很久没有被访问到,只刚刚是偶尔被访问了一次,那么它就被认为是热点数据,不会被淘汰,而有些key将来是很有可能被访问到的则被淘汰了。如果使用LFU算法则不会出现这种情况,因为使用一次并不会使一个key成为热点数据。LFU原理使用计数器来对key进行排序,每次key被访问的时候,计数器增大。计数器越大,可以约等于访问越频繁。具有相同引用计数的数据块则按照时间排序,计数器区间是0-255。
